El patrón de arquitectura microservicios está ganando rápidamente terreno en la industria como una alternativa viable a las aplicaciones monolíticas y arquitecturas orientadas al servicio. Debido a que este patrón de arquitectura sigue evolucionando, hay mucha confusión en la industria acerca de lo que es este patrón y cómo se implementa.
Independientemente de la topología o el estilo de implementación elegidos, hay varios conceptos básicos comunes que se aplican al patrón de arquitectura general. El primero de estos conceptos es la noción de unidades desplegadas separadamente. Cada componente de la arquitectura de microservicios se despliega como una unidad separada, permitiendo un despliegue más fácil a través de una tubería de entrega efectiva y simplificada, mayor escalabilidad y un alto grado de aplicación y desacoplamiento de componentes dentro de su aplicación.
Quizás el concepto más importante para entender con este patrón es la noción de un componente de servicio. En lugar de pensar en los servicios dentro de una arquitectura de microservicios, es mejor pensar en los componentes del servicio, que pueden variar en granularidad de un solo módulo a una gran parte de la aplicación. Los componentes de servicio contienen uno o más módulos (por ejemplo, clases de Java) que representan una función de un solo propósito (por ejemplo, proporcionar el tiempo para una ciudad o ciudad específica) o una parte independiente de una aplicación empresarial grande. Diseñar el nivel adecuado de granularidad del componente de servicio es uno de los mayores desafíos dentro de una arquitectura de microservicios.
Otro concepto clave dentro del patrón de arquitectura de microservicios es que es una arquitectura distribuida, lo que significa que todos los componentes dentro de la arquitectura están completamente desacoplados entre sí y se accede a través de algún tipo de protocolo de acceso remoto (por ejemplo, JMS, AMQP, REST, SOAP, RMI, etc.). La naturaleza distribuida de este patrón de arquitectura es cómo consigue algunas de sus características de escalabilidad y despliegue superiores.
Existen docenas de implementaciones de este patrón arquitectonico, pero las más comunes son: basado en un API REST, basado en una aplicación REST y de mensajería centralizada.
La topología de API REST es útil para los sitios web que desean exponer servicios atravez de una API. Un ejemplo de estos son las APIs que proveen servicios de Google, Yahoo o/y Amazon.
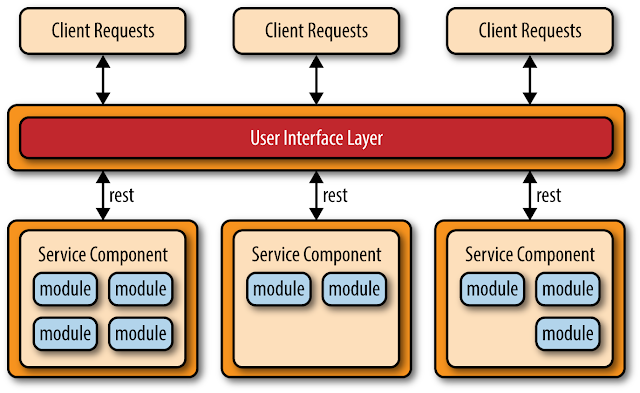
La topologia basada en REST es un tanto diferente a la anterior dado que las solicitudes del cliente se reciben a través de pantallas de aplicaciones empresariales tradicionales basadas en web o en clientes en lugar de a través de una simple capa API. La capa de interfaz de usuario de la aplicación se despliega como una aplicación web separada que accede de forma remota a componentes de servicio desplegados por separado (funcionalidad empresarial) a través de simples interfaces basadas en REST. Los componentes de servicio en esta topología difieren de los de la topología basada en API-REST en que estos componentes de servicio tienden a ser más grandes, de grano más grueso y representan una pequeña porción de la aplicación empresarial general. Esta topología es común para las aplicaciones empresariales pequeñas y medianas que tienen un grado relativamente bajo de complejidad.
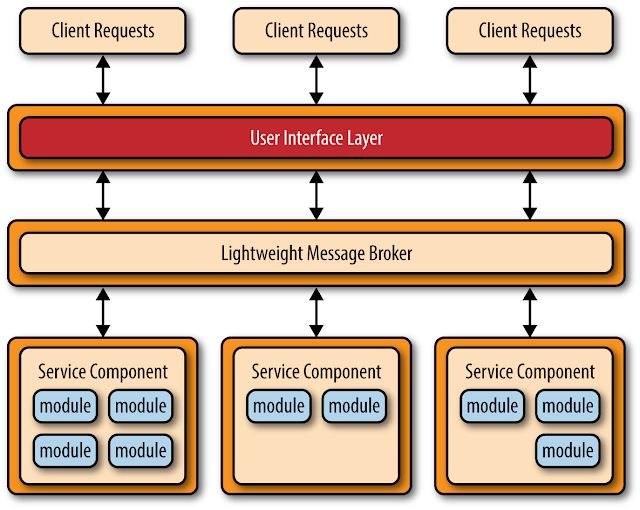
Otro enfoque común dentro del patrón de arquitectura de microservicios es la topología de mensajería centralizada. Esta topología es similar a la topología anterior basada en REST, excepto que en lugar de usar REST para acceso remoto, esta topología utiliza un intermediario de mensajes centralizado ligero (por ejemplo, ActiveMQ, HornetQ, etc.). Es de vital importancia al considerar esta topología no confundirlo con el patrón de arquitectura orientada al servicio o considerarlo "SOA-Lite". El agente de mensajes ligeros que se encuentra en esta topología no realiza ninguna orquestación, transformación o enrutamiento complejo. Es sólo un transporte ligero para acceder a los componentes de servicio remotos.
La topología de mensajería centralizada se encuentra típicamente en aplicaciones de negocios más grandes o aplicaciones que requieren un control más sofisticado sobre la capa de transporte entre la interfaz de usuario y los componentes de servicio. Los beneficios de esta topología sobre la simple topología basada en REST discutida anteriormente son mecanismos avanzados de colas, mensajería asíncrona, monitoreo, manejo de errores y mejor balanceo de carga y escalabilidad. El único punto de fallo y los problemas de cuello de botella arquitectónico generalmente asociados con un intermediario centralizado se abordan a través de la agrupación de intermediarios y de la federación de intermediarios (dividir una única instancia de intermediario en múltiples instancias de intermediario para dividir la carga de procesamiento de mensajes en función de las áreas funcionales del sistema).
El patrón de arquitectura de microservicios resuelve muchos de los problemas comunes encontrados tanto en aplicaciones monolíticas como en arquitecturas orientadas a servicios. Dado que los principales componentes de la aplicación se dividen en unidades más pequeñas, desplegadas por separado, las aplicaciones creadas utilizando el patrón de arquitectura de microservicios son generalmente más robustas, proporcionan una mejor escalabilidad y pueden soportar más fácilmente la entrega continua.
Otra ventaja de este patrón es que proporciona la capacidad de realizar despliegues de producción en tiempo real, lo que reduce significativamente la necesidad de los tradicionales despliegues mensuales o de fin de semana de "big bang". Dado que el cambio se suele aislar a componentes de servicio específicos, sólo es necesario desplegar los componentes de servicio que cambian. Si sólo tiene una única instancia de un componente de servicio, puede escribir código especializado en la aplicación de interfaz de usuario para detectar un despliegue en caliente activo y redirigir a los usuarios a una página de error o una página de espera. Alternativamente, puede intercambiar varias instancias de un componente de servicio durante y después de una implementación en tiempo real, lo que permite una disponibilidad continua durante los ciclos de implementación (algo que es muy difícil de hacer con el patrón de arquitectura en capas).
Una última consideración a tener en cuenta es que, dado que el patrón de arquitectura de los micro-servicios es una arquitectura distribuida, comparte algunos de los mismos problemas complejos encontrados en el patrón de arquitectura impulsado por eventos, incluyendo creación de contrato, mantenimiento y administración, disponibilidad remota del sistema, autenticación y autorización de acceso remoto.



 En el otro extremo de la jerarquía están los tipos Nothing y Null. Null es un tipo que tiene una sola instancia null, el desarrollador puede asignar null a cualquier referencia pero no a cualquier valor. Por ejemplo no se le puede asignar null a un valor entero.
En el otro extremo de la jerarquía están los tipos Nothing y Null. Null es un tipo que tiene una sola instancia null, el desarrollador puede asignar null a cualquier referencia pero no a cualquier valor. Por ejemplo no se le puede asignar null a un valor entero.





















 Campos Abstractos
Campos Abstractos

