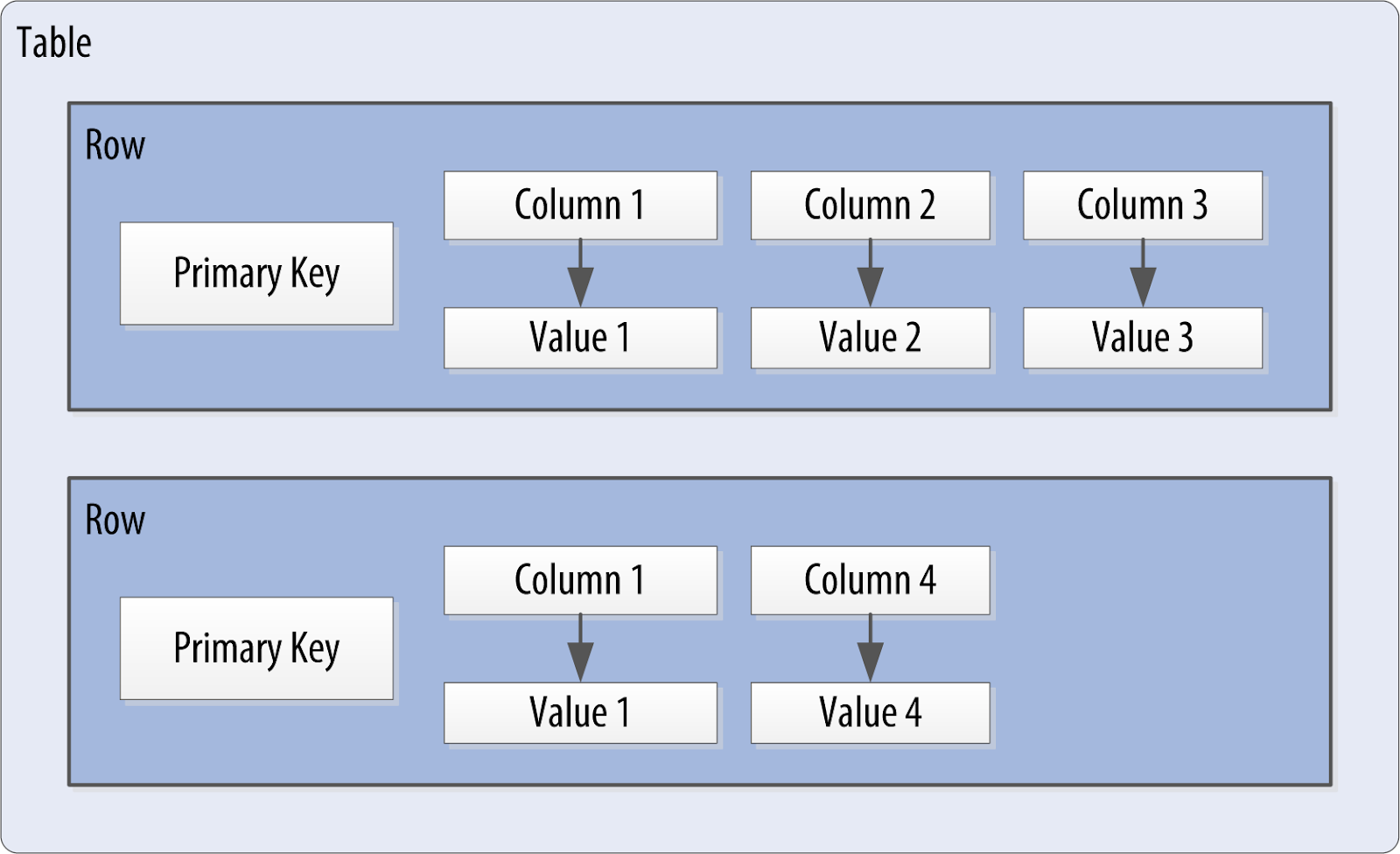
Vamos a crear un proyecto webflux utilizando Cassndra.
Primero creamos un proyecto Spring Boot y agregamos las dependencias necesarias:
- spring-boot-starter-webflux
- spring-boot-starter-data-cassandra-reactive
Si utilizamos maven el archivo pom.xml tendria estas dependencias :
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-cassandra-reactive</artifactId>
</dependency>
<dependency>
<groupId>com.datastax.oss</groupId>
<artifactId>java-driver-core</artifactId>
</dependency>
</dependencies>
Si usamos gradle seria algo así :
implementation("org.springframework.boot:spring-boot-starter-data-cassandra-reactive")
implementation("org.springframework.boot:spring-boot-starter-webflux")
Agregamos la configuración de Cassandra en application.yml:
spring:
data:
cassandra:
contact-points: [localhost]
port: 9042
keyspace-name: demo_keyspace
schema-action: create-if-not-exists
o en el properties:
spring.cassandra.contact-points=127.0.0.1
spring.cassandra.port=9042
spring.cassandra.keyspace-name=demo_keyspace
spring.cassandra.schema-action= create-if-not-exists
spring.cassandra.local-datacenter=datacenter1
Ahora vamos a definir una entidad para guardar y recuperar:
import org.springframework.data.annotation.Id;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
@Table("products")
public class Product {
@Id
@PrimaryKey
private String id;
private String name;
private double price;
// Getters y setters
}
Crea un repositorio usando ReactiveCassandraRepository:
import org.springframework.data.cassandra.repository.ReactiveCassandraRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ProductRepository extends ReactiveCassandraRepository<Product, String> {
}
Ahora hacemos el servicio:
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@Service
public class ProductService {
private final ProductRepository productRepository;
public ProductService(ProductRepository productRepository) {
this.productRepository = productRepository;
}
public Flux<Product> getAllProducts() {
return productRepository.findAll();
}
public Mono<Product> getProductById(String id) {
return productRepository.findById(id);
}
public Mono<Product> createProduct(Product product) {
return productRepository.save(product);
}
public Mono<Void> deleteProduct(String id) {
return productRepository.deleteById(id);
}
}
Ahora creamos un controlador REST con WebFlux:
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@RestController
@RequestMapping("/products")
public class ProductController {
private final ProductService productService;
public ProductController(ProductService productService) {
this.productService = productService;
}
@GetMapping
public Flux<Product> getAllProducts() {
return productService.getAllProducts();
}
@GetMapping("/{id}")
public Mono<Product> getProductById(@PathVariable String id) {
return productService.getProductById(id);
}
@PostMapping
public Mono<Product> createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
@DeleteMapping("/{id}")
public Mono<Void> deleteProduct(@PathVariable String id) {
return productService.deleteProduct(id);
}
}
Por ultimo tenemos que agregar las anotaciones @EnableReactiveCassandraRepositories y @Push a nuestro application :
@SpringBootApplication
@EnableReactiveCassandraRepositories
@Push
class ApplicationDemo : AppShellConfigurator
fun main(args: Array<String>) {
runApplication<ApplicationDemo>(*args)
}
Y ahora podemos probar nuestros servicios.