Download IT Guides!
|
sábado, 31 de agosto de 2019
Libros de Java Code Geeks




martes, 27 de agosto de 2019
Datos en Factor
 Sigo con Factor y sus pilas.
Sigo con Factor y sus pilas.Factor usa datos estandar como String, números, booleans y secuencias.
Veamos :
Tenemos booleanos:
IN: scratchpad 4 2 = .
f
IN: scratchpad 4 2 > .
t
IN: scratchpad "same" "same" = .
t
IN: scratchpad "same" length "diff" length = .
t
En Factor cualquier valor excepto f es considerado como true, incluyendo 0, el string vacio o la secuencia vacia.
Factor soporta una secuencia como un tipo de datos. Se puede crear una lista con { } y los valores separados por espacio un ejemplo sería : { 4 3 2 1 } Es necesario el espacio luego de la llaves, similar a lisp.
Los mapas son colecciones key-value, veamos un ejemplo :
{ { "one" 1 } { "two" 2 } { "three" 3 } { "four" 4 } }
Con la palabra of y at podemos acceder a el valor con una key :
IN: scratchpad { { "one" 1 } { "two" 2 } { "three" 3 } } "one" of .
1
IN: scratchpad "two" { { "one" 1 } { "two" 2 } { "three" 3 } } at .
2
Inyección de dependencia de tiempo de compilación

Un enfoque alternativo que es popular en el desarrollo de Scala es utilizar la inyección de dependencia de tiempo de compilación. Esta técnica se puede lograr mediante la construcción manual y el cableado de dependencias. Existen otras técnicas y herramientas más avanzadas, como herramientas de cableado automático basadas en macros, técnicas de cableado automático implícito y varias formas del cake pattern.
Inyectar dependencias en tiempo de compilación permite aprovechar el compilador para verificar que cada controlador en su aplicación tenga acceso a todos los componentes que necesita. Eso significa que no necesita preocuparse por los errores de tiempo de ejecución que causan bloqueos y una mala experiencia para sus usuarios. De hecho, la DI en tiempo de compilación (y la tipificación estática en general) pueden reducir la necesidad de un subconjunto de tipos comunes de pruebas unitarias.
El uso de parámetros de constructor es un enfoque simple y directo para definir dependencias en tiempo de compilación. Veamos un ejemplo del framework play:
class Controller( val controllerComponents: ControllerComponents,
userModel: UserModel) extends BaseController {
def user() = Action {
request => Ok(Json.toJson(userModel.getUsernames()))
}
}
Se puede decir que la siguiente clase "depende de" una instancia de ControllerComponents y una instancia de UserModel. Esto es tan simple como especificar dependencias. No hay magia, solo dices qué componente quieres y lo obtienes. Configurar cómo se proporcionan las dependencias requiere un poco más de trabajo. Aquí es donde entra el cargador de aplicaciones de play.
class Loader extends ApplicationLoader {
def load(context: Context): Application = {
LoggerConfigurator(context.environment.classLoader).foreach {
_.configure(context.environment)
}
new Components(context).application
}
}
class Components(context: Context) extends BuiltInComponentsFromContext(context) {
override lazy val httpFilters = Nil
Lazy val userModel: UserModel = new UserModel()
lazy val controller: Controller = new Controller(controllerComponents, userModel)
lazy val router: Router = new Routes(httpErrorHandler, controller)
}
La clase Loader se requiere principalmente para garantizar que la aplicación esté configurada correctamente cuando se carga. La inyección de dependencias ocurre en la clase Componentes. Una vez más, no hay magia aquí: simplemente crea y pasa instancias a componentes que las necesitan. BuiltInComponentsFromContext proporciona un puñado de componentes de Play predeterminados que son útiles. En este caso, uso el componente ControllerComponents para nuestro controlador y un HttpErrorHandler para el constructor de Rutas.
Para aplicaciones simples, la inyección manual de dependencias es bastante simple. Sin embargo, incluso en aplicaciones simples, agregar una dependencia a un controlador requiere que modifique tanto el controlador como el cargador de aplicaciones. Este proceso se ve exacerbado por el constructor de Rutas que genera Play. Cada clase a la que haga referencia en conf / routes se traducirá en un parámetro constructor del objeto Routes. Eso significa que agregar una clase de controlador requiere que crees una instancia de la clase y la pases explícitamente al constructor de Rutas. Para empeorar las cosas, si reordena su archivo conf / routes o agrega una nueva ruta en algún lugar en el medio, su objeto Routes generado tendrá un nuevo orden para sus parámetros de constructor, y tendrá que arreglarlo manualmente también.
La inyección manual en tiempo de compilación no es escalable y creará mucho trabajo adicional en aplicaciones más complejas. Aquí es donde entra MacWire.
MacWire es una macro muy ligera que genera automáticamente llamadas de constructores. Eso es casi todo lo que hace (está bien, tiene algunas otras características, pero solo nos importa esta por ahora). Usando MacWire, cambié la clase de Componentes anterior a la siguiente:
class Components(context: Context) extends BuiltInComponentsFromContext(context) {
override lazy val httpFilters = Nil
lazy val userModel: UserModel = wire[UserModel]
lazy val controller: Controller = wire[Controller]
lazy val router: Router = {
val prefix = "/"
wire[Routes]
}
}
Notarás dos cambios importantes.
Primero, todas las llamadas "nuevas" han sido reemplazadas por wire [ClassName]. Esta es la macro que genera las llamadas "nuevas". Para ello, examina el constructor predeterminado para la clase especificada y luego busca valores del mismo tipo en el ámbito actual. El wire [Controlador] se expandirá a un nuevo Controlador (controllerComponents, userModel). Ese es exactamente el mismo código que escribimos manualmente arriba. Wire sigue las reglas normales de alcance con las que ya está familiarizado en Scala. Si hay varias instancias que cumplirán una dependencia, el cable fallará en tiempo de compilación diciendo que no puede decidir qué instancia usar. Tendrá que resolver esta ambigüedad manualmente. MacWire proporciona calificadores para simplificar este proceso cuando sea necesario.
En segundo lugar, la definición de enrutador cambió. El constructor predeterminado de Rutas requiere un argumento de prefijo de cadena, mientras que el constructor utilizado manualmente en nuestro ejemplo original anterior no es el constructor predeterminado y no requiere este argumento. Envolví el prefijo en el alcance del bloque de la llamada por cable para no filtrar accidentalmente el prefijo en otros componentes que podrían necesitar un parámetro de cadena. En proyectos más grandes, esto se vuelve más valioso. En este ejemplo, todo habría funcionado bien si definiera el prefijo fuera del bloque Router.
Ahora, agregar una dependencia (o eliminar una dependencia) de un controlador solo requiere que modifique el controlador en sí. Entonces, si necesita acceso a la configuración de la aplicación, puede agregar un parámetro de constructor con el tipo Configuración al controlador y, como por arte de magia, inyectará un objeto de Configuración. Aún mejor, agregar, eliminar o reordenar rutas en conf / routes se vuelve mucho más fácil porque ya no tiene que preocuparse por el orden de los parámetros de Rutas o cualquier cosa más allá de las clases específicas para las que necesita proporcionar instancias.
Una última nota sobre MacWire: se debe usar lazy val. Esto permite especificar dependencias complicadas sin preocuparse por el orden de inicialización entre los diferentes componentes. Todos se crearán a pedido y evitará posibles excepciones de puntero nulo. También puede usar defs si prefiere que cada clase que depende de su def obtenga una nueva instancia en lugar de una instancia compartida.
Y me quedo relargo el post en otro vamos a ver el cake pattern.
Indice TIOBE de agosto
Hace rato que no publico el indice tiobe de lenguajes, veamos :


Como se puede ver Python va subiendo tranquilo, a mi entender esto viene de la mano de las tecnologías de machine learnig que cada vez están más presentes y todas las librerías están en Python.
Otro lenguaje que viene creciendo es Groovy, a mi entender gracias a Spring y pivotal
Dejo link:
https://www.tiobe.com/tiobe-index/


Como se puede ver Python va subiendo tranquilo, a mi entender esto viene de la mano de las tecnologías de machine learnig que cada vez están más presentes y todas las librerías están en Python.
Otro lenguaje que viene creciendo es Groovy, a mi entender gracias a Spring y pivotal
Dejo link:
https://www.tiobe.com/tiobe-index/
sábado, 24 de agosto de 2019
Matematicas en Factor

La palabras +, -, * y / toman dos valores de la pila y retorna el valor a la pila. El . toma un valor de la pila y lo imprime.
IN: scratchpad 40 2 + .
42
IN: scratchpad 40 2 - .
38
IN: scratchpad 20 9 * 5.0 / 32 + .
68.0
Muy similar a lisp pero utiliza notación postfija.
IN: scratchpad 5 4 * 20 + .
40
IN: scratchpad 20 5 + 4 * .
100
Como utiliza notación postfija no existe ambiguedad.
viernes, 23 de agosto de 2019
¿Cuál es la diferencia entre un closure y una lambda?

Una lambda es solo una función anónima, una función definida sin nombre. En algunos lenguajes, como Scheme, son equivalentes a funciones con nombre. De hecho, la definición de la función se reescribe como un enlace interno de una lambda a una variable. En otros lenguajes, como Python, hay algunas distinciones (bastante innecesarias) entre ellos, pero de lo contrario se comportan de la misma manera.
Un closure es cualquier función que se cierra sobre el entorno en el que se definió. Esto significa que puede acceder a variables que no están en su lista de parámetros. Ejemplos:
def func (): return h
def otrofunc (h):
return func ()
Esto provocará un error, porque func no se cierra sobre el entorno en otrofunc - h no está definido. func solo cierra sobre el entorno global. Esto funcionará de esta manera :
def otrofunc (h):
def func (): retorno h
return func ()
Porque aquí, func se define en otrofunc.
Otro punto importante: func continuará cerrándose sobre el entorno de otrofunc incluso cuando ya no se evalúe en otrofunc. Este código también funcionará:
def anotherfunc(h):
def func(): return h
return func
print anotherfunc(10)()
Esto imprimirá 10.
Esto no tiene nada que ver con las lambdas: son dos conceptos diferentes (aunque relacionados).
sábado, 17 de agosto de 2019
Factor un lenguaje de programación orientado a pilas
 Sigo con Factor y sus pilas.
Sigo con Factor y sus pilas.Vamos a hacer un “hola mundo” en Factor. Empezamos indicando el vocabulario “scratchpad”, pero por ahora no vamos a profundizar en eso. Luego vamos a escribir nuestro “hola mundo”
IN: scratchpad "Hello, world" print
Hello, world
Factor introduce a “Hola Mundo” a la pila y la función print toma de la pila el parametro y se ejecuta.
Introduciendo clear, factor limpia la pila y luego si ejecutamos “Hola Mundo”. Factor nos indica que esto se encuentra en la pila:
IN: scratchpad clear
IN: scratchpad "Hello, world"
--- Data stack:
"Hello, world"
Podemos introducir otro string a la pila :
IN: scratchpad "Hello, Factor"
--- Data stack:
"Hello, world"
"Hello, Factor"
Si ahora intentamos imprimir Factor va utilizar el ultimo valor insertado en la pila :
IN: scratchpad print
Hello, Factor
--- Data stack:
"Hello, world"
Si ejecutamos una funcion que retorne un valor, factor pondra ese valor en la pila.
IN: scratchpad length
--- Data stack:
12
La palabra (recuerden que las funciones se denominan "palabras") length tomó "Hello, world" de la pila y retorno la longitud de la cadena de nuevo y la puso en la pila. Cada palabra en Factor toma cero o más valores de la pila y llena cero o más valores en la pila. La siguiente palabra luego funciona con la pila resultante, y así sucesivamente.
Cuando se ejecuta un programa Factor, el efecto neto de todas las palabras reunidas juntas debe ser consistente, con cada palabra que tenga al menos tantos valores en la pila como esperan extraer, y eliminar tantos valores como afirman. Cuando la pila contiene más valores de los que necesita usar una palabra, los valores adicionales simplemente permanecen en la pila.
Un dato más los comentarios comienzan con un ! seguido de un espacio, veamos un ejemplo :
! This is a comment
"Hello, world" print ! This prints "Hello, world"
Curso de Angular Gratuito!!!

Me llego la invitación a un curso de angular gratuito, es una muy buena posibilidad para aprender este framework tan utilizado. La invitación dice lo siguiente :
Angular es un framework de desarrollo para JavaScript creado por Google. Su finalidad es la de facilitar el desarrollo de aplicaciones web SPA (Single Page Application, Aplicación de Página Única) proporcionando herramientas para trabajar con los elementos de una web de una manera más sencilla y óptima.
Inicio del Curso: 19 de Agosto 2019
Duración: 2 meses
Modalidad: 100% OnLine (SUTIA e-Learning)
Costo: ¡¡¡Gratuito!!! (por lanzamiento de la Plataforma SUTIA e-Learning)
Dejo link: http://sutia.com.ar/angular2019/
Entendiendo el Execution Plan en MySql

No sabia que Mysql tenia la clausula PLAN EXPLAIN y la tiene! Pero para que sirve?
Dependiendo de los detalles de sus tablas, columnas, índices y las condiciones en su cláusula WHERE, el optimizador MySQL considera muchas técnicas para realizar eficientemente las búsquedas involucradas en una consulta SQL.
Se puede realizar una consulta en una tabla enorme sin leer todas las filas; se puede realizar una unión que involucre varias tablas sin comparar cada combinación de filas. El conjunto de operaciones que el optimizador elige para realizar la consulta más eficiente se denomina "plan de ejecución de consultas", y este se puede ver ejecutando el PLAN EXPLAIN. Sus objetivos son reconocer los aspectos que indican que una consulta está bien optimizada y aprender la sintaxis SQL y las técnicas de indexación para mejorar el plan si hay algunas operaciones ineficientes.
La declaración EXPLAIN proporciona información sobre cómo MySQL ejecuta las consultas.
Cuando precede a una instrucción SELECT con la palabra clave EXPLAIN, MySQL muestra información del optimizador sobre el plan de ejecución de la instrucción. Es decir, MySQL explica cómo procesaría la declaración, incluida la información sobre cómo se unen las tablas y en qué or
Con la ayuda de EXPLAIN, puede ver dónde debe agregar índices a las tablas para que la instrucción se ejecute más rápido mediante el uso de índices para buscar filas. También puede usar EXPLAIN para verificar si el optimizador se une a las tablas en un orden óptimo. Para dar una pista al optimizador para que use un orden de unión correspondiente al orden en que se nombran las tablas en una instrucción SELECT, comience la instrucción con SELECT STRAIGHT_JOIN en lugar de solo SELECT.
Si tenemos un problema con los índices que no se usan cuando sabemos que deberían ser usados, debemos ejecutar ANALYZE TABLE para actualizar las estadísticas de la tabla, como la cardinalidad de las claves, que pueden afectar las elecciones que realiza el optimizador.
EXPLAIN devuelve una fila de información para cada tabla utilizada en la instrucción SELECT. Enumera las tablas en la salida en el orden en que MySQL las leería mientras procesa la declaración. MySQL resuelve todas las uniones utilizando un método de unión de bucle anidado. Esto significa que MySQL lee una fila de la primera tabla y luego encuentra una fila coincidente en la segunda tabla, la tercera tabla, etc. Cuando se procesan todas las tablas, MySQL genera las columnas seleccionadas y retrocede a través de la lista de tablas hasta que se encuentra una tabla para la cual hay más filas coincidentes. La siguiente fila se lee de esta tabla y el proceso continúa con la siguiente tabla.
Cuando se usa la palabra clave EXTENDED, EXPLAIN produce información adicional que se puede ver emitiendo una declaración SHOW WARNINGS después de la declaración EXPLAIN. EXPLAIN EXTENDED también muestra la columna filtrada.
En la mayoría de los casos, puede estimar el rendimiento de la consulta contando las búsquedas de disco. Para tablas pequeñas, generalmente puede encontrar una fila en una búsqueda de disco (porque el índice probablemente está en caché). Para tablas más grandes, puede estimar que, utilizando índices de árbol B, necesita esta cantidad de búsquedas para encontrar una fila: log (row_count) / log (index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1.
En MySQL, un bloque de índice suele tener 1.024 bytes y el puntero de datos suele tener cuatro bytes. Para una tabla de 500,000 filas con una longitud de valor clave de tres bytes (el tamaño de MEDIUMINT), la fórmula indica log (500,000) / log (1024/3 * 2 / (3 + 4)) + 1 = 4 búsquedas.
Este índice requeriría un almacenamiento de aproximadamente 500,000 * 7 * 3/2 = 5.2MB (suponiendo una relación de llenado del búfer de índice típico de 2/3), por lo que probablemente tenga gran parte del índice en la memoria y, por lo tanto, solo necesite una o dos llamadas para leer datos para encontrar la fila.
Sin embargo, para las escrituras, necesita cuatro solicitudes de búsqueda para encontrar dónde colocar un nuevo valor de índice y normalmente dos buscar y actualizar el índice y escribir la fila.
La discusión anterior no significa que el rendimiento de su aplicación se degenere lentamente por el registro N. Mientras el sistema operativo o el servidor MySQL guarden en caché todo, las cosas se vuelven un poco más lentas a medida que la tabla se hace más grande. Después de que los datos se vuelven demasiado grandes para ser almacenados en caché, las cosas comienzan a ir mucho más lentamente hasta que sus aplicaciones están unidas solo por búsquedas de disco (que aumentan por log N). Para evitar esto, aumente el tamaño de la caché de claves a medida que crecen los datos. Para las tablas MyISAM, el tamaño del caché de claves está controlado por la variable de sistema key_buffer_size.
Por ahora eso es todo sobre nuestro querido explain, dejo link :
https://dev.mysql.com/doc/refman/8.0/en/explain.html
https://dev.mysql.com/doc/refman/5.5/en/execution-plan-information.html
miércoles, 14 de agosto de 2019
Libros gratis de Java Code Geeks
Download IT Guides!
|




lunes, 12 de agosto de 2019
Haciendo aplicaciones políglotas con GraalVM

GraalVM permite compartir el mismo runtime, eliminando la aislamiento y permitiendo la interoperabilidad entre programas que estén escritos en diferente lenguajes. Puede correr como “standalone” o por medio de la Open-Jdk o Node.js o por la base de datos oracle.
GraalVM permite escribir poliglotas programas con cero overhead y con alta interoperabilidad. De esta manera que se pueden escribir diferentes partes del código en diferentes lenguajes.
const express = require('express');
const app = express();
app.listen(3000);
app.get('/', function(req, res) {
var text = 'Hello World!';
const BigInteger = Java.type(
'java.math.BigInteger');
text += BigInteger.valueOf(2)
.pow(100).toString(16);
text += Polyglot.eval(
'R', 'runif(100)')[0];
res.send(text);
})
También podemos crear imágenes de nuestras aplicaciones Java, lo que permite que corran mucho más rápido, en una plataforma determinada.
$ javac HelloWorld.java
$ time java HelloWorld
user 0.070s
$ native-image HelloWorld
$ time ./helloworld
user 0.005s
GraalVm puede ser embebido en aplicaciones Java que utilicen el openjdk o node.js o base de datos oracle. De esta manera podemos ejecutar código de otro lenguaje :
import org.graalvm.polyglot.*;
public class HelloPolyglot {
public static void main(String[] args) {
System.out.println("Hello Java!");
Context context = Context.create();
context.eval("js",
"print('Hello JavaScript!');");
}
}
Es muy bueno, dejo el link:
https://www.graalvm.org/
sábado, 10 de agosto de 2019
Unificando el modelo de programación de motores mapreduce con Apache Beam

Ahora bien en un momento nos enteramos que nuestra aplicación funcionaria mejor con Apache Flink o por un tema comercial queremos migrar a Cloud Dataflow de google, no sé la realidad cambia y nosotro no vamos a poder cambiar tan fácil de tecnología, porque estamos atrapados en nuestros RDDs y en el contexto de Spark.
Por esta razón se invento Apache Beam, la idea es unificar el modelo de programación de frameworks map-reduce, streams o big data en general para poder migrar fácilmente de framework a framework.
Apache Beam es un modelo unificado de código abierto para definir tuberías de procesamiento paralelo de datos por lotes y de transmisión. Usando el SDK de Beam, creamos un programa que define tuberías que es ejecutada por uno de los back-end de procesamiento distribuido compatibles con Apache Apex, Apache Flink, Apache Spark y Google Cloud Dataflow. Además Apache Beam SDK es de código abierto.
Beam es particularmente útil para tareas paralelas de procesamiento de datos, en las que el problema se puede descomponer en muchos paquetes más pequeños de datos que se pueden procesar de forma independiente y en paralelo. También puede usar Beam para tareas de Extracción, Transformación y Carga (ETL) e integración de datos puros. Estas tareas son útiles para mover datos entre diferentes medios de almacenamiento y fuentes de datos, transformar datos en un formato más deseable o cargar datos de un sistema.
Los SDK de Beam proporcionan un modelo de programación unificado que puede representar y transformar conjuntos de datos de cualquier tamaño, ya sea que la entrada sea un conjunto de datos finito de una fuente de datos por lotes o un conjunto de datos infinito de una fuente de datos de transmisión (streams). Los SDK de Beam utilizan las mismas clases para representar datos acotados y no acotados, y las mismas transformaciones funcionan para esos datos.
Beam actualmente admite los siguientes lenguajes:
- Java Java logo
- Python Python logo
- Go
- Scala por medio de la librería Scio.
Algo importante es que tenemos un sdk por lenguaje, y es medio obvio dado que esto no corre solo sobre la jdk. Esto me suena tramposo porque no es que para todos los lenguajes tenes todos los frameworks. Sino que para algunos lenguajes tenes algunos frameworks de esa tecnología.

Los Beam Pipeline Runners traducen la tubería de procesamiento de datos al framework back-end que deseemos. Cuando ejecute su programa Beam, deberá especificar un corredor apropiado para el back-end.
Beam actualmente admite Runners que funcionan con los siguientes back-end de procesamiento distribuido:
- Apache Apex
- Apache Flink
- Apache Gearpump (incubating)
- Apache Samza
- Apache Spark
- Google Cloud Dataflow
- Hazelcast Jet
Dejo link: https://beam.apache.org/
jueves, 8 de agosto de 2019
Se encuentran abiertas las inscripciones para los cursos Gugler!!!
| Me llego este mail de los amigos de Gugler : | |||||
| PRENSA GUGLER LAB 20192019 | |||||
Estimado Goette Emanuel : Las clases estarían iniciándose el martes 3, miércoles 4, jueves 5, viernes 6 o sábado 7 de Septiembre, según el curso y modalidad que elegiste. Inscribirte: clic aquí Cursos, Horarios y comisiones: clic aquí. | Dictamos nuestros cursos en la Facultad de Ciencia y Tecnología, perteneciente a la Universidad Autónoma de Entre Ríos. En nuestro portafolio de capacitación encontrarás: MODALIDAD PRESENCIAL
| ||||
| Si deseas comunicarte con nosotros, te recordamos que podes hacerlo a través de los siguientes portales, en los cuales encontrarás información sobre Gugler. TEL: (0343) - 4975066 Interno 119 Sitio Oficial: www.gugler.com.ar Campus: campusvirtual.gugler.com.ar Sistema de Gestión Cursos: sgc.gugler.com.ar Sistema de Gestión Cursos Móvil: Aquí Sistema de Documentación: sgd.gugler.com.ar Sistema de Validación: giua.gugler.com.ar |
| ||||
| GUGLER PRESS | |||||

sábado, 3 de agosto de 2019
Componiendo funciones con Factor

La composición de funciones es un concepto muy importante permite dividir las funciones en funciones más pequeñas y comenzar con la entrada, pásela a través de una serie de funciones y obtener una salida de esta manera la salida de una función es la entrada a la siguiente función y así sustantivamente hasta obtener la salida. Por lo tanto cada función es pequeña y enfocada. Se resuelve problemas creando y conectando bloques de código.
Veamos un ejemplo pero primero JavaScript :
ar x = f(42);
var y = g(x);
return h(y);
o más resumido:
return h(g(f(42)));
En factor sería :
42 f g h
Sin nombres de variables y sin paréntesis, puntos o cualquier otro signo de puntuación para indicar la composición de la función. Se da a entender que el resultado de llamar a una función (llamada word o "palabra" en Factor) . Factor maneja esto automáticamente utilizando una pila, que es simplemente un contenedor que contiene valores. Una palabra toman su entrada de la pila y empujan su resultado a la pila, que luego es operada por la siguiente palabra.
Observe también que las palabras f g h se llaman en el mismo orden en que las leemos, de izquierda a derecha.
Esta llamada se puede ver como el pipe operator de Elixir :
other_function(2) |> new_function() |> baz() |> bar() |> foo()
o el pipe operator de linux donde la salida de una operación es la entrada para otra, podemos hacer :
$ history | grep "apt"
En la versión de JavaScript, f es una función, y los paréntesis en f (42) indican que se aplica f al valor 42. Esto hace que JavaScript sea un lenguaje aplicativo. La mayoría de los otros lenguajes, como Java, Ruby, Python, Clojure, Scala, Haskell y Erlang, son aplicativos.
Factor es un lenguaje concatenante porque en lugar de aplicar funciones (o palabras), las concatena, simplemente escribiéndolas una tras otra.
La composición de funciones es la forma predeterminada de tratar una expresión como f g h. Otros lenguajes concatenativos incluyen Forth, Joy, PostScript, Cat, Om, Retro y Kitten. Si está familiarizado con Forth o Joy, notará algunas similitudes en Factor.
En lugar de escribir :
wrapWordsAsList (capitalize (strip (text)))
puedes escribir :
text strip capitalize wrapWordsAsList
Es una hermosa expresión!!!
Dejo link: https://factorcode.org/
jueves, 1 de agosto de 2019
Ploteando un dataframe con R en Spark.

// Primero leo el archivo
csvPath <- "/home/spark/filmsCount.csv/part.csv"
df <- read.df(csvPath, "csv", header = "false", inferSchema = "true")
//Luego imprimo sus valores para saber que están bien.
head(df)
showDF(df)
//Ahora transformo el dataframe de spark a un dataframe plano de R
dfR <- collect(df) //Es importante pasar de dataframe de spark a dataframe de R
//Importo la librería de plot de R
library('txtplot')
//Gráfico la densidad a los 20 primeros valores.
txtdensity( dfR[1:20,2] )
//Gráfico la densidad a todos los valores.
txtdensity( dfR[,2] )
//Gráfico la densidad a todos los valores con un barchart
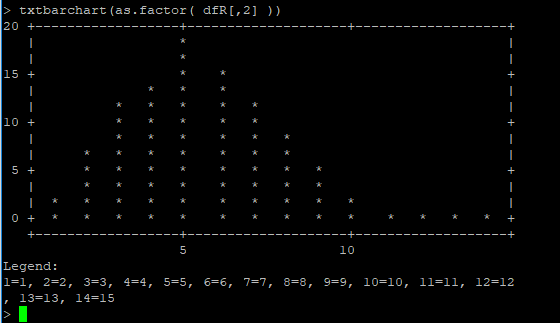
txtbarchart(as.factor( dfR[,2] ))
Y listo!!
Y te queda así :


Primeros pasos con Flutter parte 3, más Flutter que nunca!

Veamos el directorio de un proyecto en Flutter.
Directorio lib, donde va a estar toda la acción de desarrollo, y el archivo main.dart el cual es el punto de entrada de ejecución de la aplicación.
También podemos ver:
Directorios Android / IOS: contienen proyectos generados, 100% nativos, que pueden abrirse en las IDE correspondientes a cada plataforma.
Assets: Directorio para incluir imágenes/fuentes. Todos los archivos en esta carpeta se incluirán de manera automática en el bundle final. También podemos agregar directorios y archivos.
Test: Directorio para clases y archivos de unit testing.
 El archivo main es el punto de entrada de una aplicación. El runtime buscara el método “main” dentro de este archivo y debe invocar el método runApp con un widget.
El archivo main es el punto de entrada de una aplicación. El runtime buscara el método “main” dentro de este archivo y debe invocar el método runApp con un widget.En flutter, todo es un widget. Un icono, una imagen, un botón y hasta los elementos de layout, como un contenedor, una Column, Row o un Stack todos son widgets; y tanto cada pantalla como nuestra app final, será simplemente, una composición de dichos widgets.
Un widget es representado por una clase, que debe heredar de la clase del framework StatelessWidget o StatefulWidget (dependiendo de si nuestro widget tiene información estado o no), y debe además sobrescribir el método build. Dicho método debe estar en todo widget, y debe retornar un Widget.
Cada widget puede contener un hijo, que se especifica en su propiedad child. En el caso de algunos widgets de layout como “Row” o “Column”, se pueden especificar varios widgets hijos, en la propiedad children. Flutter construye los widgets a modo de árbol, invocando el método build de cada widget.
El manejo de estado más básico de un widget en Flutter, se hace mediante llamados al método setState. SetState notifica al framework del cambio de estado, y redibuja los widgets que sean necesarios.
El manejo de estado mediante el método setState puede funcionar para aplicaciones muy pequeñas, o para manejo de estado relacionado al widget en sí, Flutter ofrece mejores maneras para manejo de estado más complejo.
 Una pregunta muy común que surge a la hora de ver setState como método de manejo de estado es, ¿“Que pasa si quiero compartir información entre pantallas y widgets?” Si bien siempre podemos pasar la información mediante parámetros en los constructores, es una solución poco práctica y engorrosa. Para eso, Flutter ofrece Inherited Widget
Una pregunta muy común que surge a la hora de ver setState como método de manejo de estado es, ¿“Que pasa si quiero compartir información entre pantallas y widgets?” Si bien siempre podemos pasar la información mediante parámetros en los constructores, es una solución poco práctica y engorrosa. Para eso, Flutter ofrece Inherited WidgetAntes hablamos como los widgets en Flutter se anidan y estructuran en un árbol. Para que un widget pueda acceder a otro que se encuentra arriba en el árbol es que tenemos Inherited Widget. A nivel de código, no es más que otro widget, simplemente debe heredar de la clase InheritedWidget e implementar el método updateShouldNotify, para definir condicionalmente cuando disparar la notificación de update.
Con este código, ya tenemos un widget que puede ser accedido por todos los widgets hijos en el árbol. El acceso al InheritedWidget se logra utilizando el método “of”. Claramente leyéndolo así suena todo muy abstracto, en un próximo post vamos con un ejemplo.
Dejo link: https://flutter.dev
SASI : Una nueva implementación del índice secundario en Cassandra

La versión Cassandra 3.4 incluía una implementación alternativa de índices secundarios conocida como SSTable Attached Secondary Index (SASI). SASI fue desarrollado por Apple y lanzado como una implementación de código abierto de la API del índice secundario de Cassandra. Como su nombre lo indica, los índices SASI se calculan y almacenan como parte de cada archivo SSTable, a diferencia de la implementación original de Cassandra, que almacena los índices en tablas separadas, "ocultas".
La implementación SASI existe junto con los índices secundarios tradicionales, y puede crear un índice SASI con el comando CQL CREATE CUSTOM INDEX:
CREATE CUSTOM INDEX user_last_name_sasi_idx ON user (last_name)
USING 'org.apache.cassandra.index.sasi.SASIIndex';
Los índices SASI ofrecen funcionalidad más allá de la implementación de índice secundario tradicional, como la capacidad de realizar búsquedas de desigualdad (mayor o menor que) en columnas indexadas. También puede utilizar la nueva palabra clave "LIKE" para realizar búsquedas de texto en columnas indexadas. Por ejemplo, podría usar la siguiente consulta para encontrar usuarios cuyo apellido comience con "N":
SELECT * FROM user WHERE last_name LIKE 'N%';
Si bien los índices SASI se desempeñan mejor que los índices tradicionales al eliminar la necesidad de leer de tablas adicionales, aún requieren lecturas de un mayor número de nodos que un diseño desnormalizado.
Libres Gratuitos!!!
|




Suscribirse a:
Entradas (Atom)
