








Seguimos con Monoides y Semigrupos.
Un semigrupo es solo la parte combinada de un monoide, sin elemento vacio.
Si bien muchos semigrupos también son monoides, hay algunos tipos de datos para los que no podemos definir un elemento vacío. Por ejemplo, acabamos de ver que la concatenación de secuencias y la suma de enteros son monoides. Sin embargo, si nos restringimos a secuencias no vacías y enteros positivos, ya no podemos definir un elemento vacío sensible. Cats tiene un tipo de datos NonEmptyList que tiene una implementación de Semigroup pero no una implementación de Monoide.
Una definición más precisa (aunque todavía simplificada) de Cats' Monoid es:
trait Semigroup[A] {
def combine(x: A, y: A): A
}
trait Monoid[A] extends Semigroup[A] {
def empty: A
}
Veremos este tipo de herencia a menudo cuando discutamos las clases de tipos. Proporciona modularidad y nos permite reutilizar el comportamiento. Si definimos un Monoide para un tipo A, obtenemos un Semigrupo gratis. De manera similar, si un método requiere un parámetro de tipo Semigroup[B], podemos pasar un Monoid[B] en su lugar.


Apache Superset es rápido, liviano, intuitivo y está repleto de opciones que facilitan a los usuarios de todos los conjuntos de habilidades explorar y visualizar sus datos, desde simples gráficos circulares hasta gráficos geoespaciales deck.gl altamente detallados.
Apache Superset proporciona:
Superset es nativo de la nube y está diseñado para tener una alta disponibilidad. Fue diseñado para escalar a grandes entornos distribuidos y funciona muy bien dentro de contenedores. Si bien puede probar fácilmente Superset en una configuración modesta o simplemente en su computadora portátil, prácticamente no hay límite para escalar la plataforma.
Superset también es nativo de la nube en el sentido de que es flexible y le permite elegir:
Superset se ejecuta actualmente a escala en muchas empresas. Por ejemplo, Superset se ejecuta en el entorno de producción de Airbnb dentro de Kubernetes y sirve a más de 600 usuarios activos diarios que ven más de 100 000 gráficos al día.
Sin más dejo link: https://superset.apache.org/

Lanzado inicialmente en 2018, Google App Engine se diseñó para facilitar a los desarrolladores la implementación y el escalado de sus aplicaciones web. App Engine actualmente es compatible con muchos lenguajes como: Java, PHP, Python, Node.js, Go, Ruby.
Los desarrolladores de Java pueden implementar aplicaciones web basadas en servlets, utilizando Java 8, Java 11 y Java 17, así como otros lenguajes JVM como Groovy y Kotlin. Además, es posible utilizar muchos frameworks, como Spring Boot, Quarkus, Vert.x y Micronaut.
Queria compartir con ustedes esta noticia, que más que nada me llamo la atención. Dado que no conozco gente que este usando App Engine y me parece que estos esfuerzos para hacer la plataforma más popular llegaron tarde.
Dejo link : https://cloud.google.com/blog/topics/developers-practitioners/open-sourcing-app-engine-standard-java-runtime
La adición de Ints es una operación binaria cerrada, lo que significa que sumar dos Ints siempre produce otro Int:
2 + 1
// res0: Int = 3
trait Monoid[A] {
def combine(x: A, y: A): A
def empty: A
}
Además de proporcionar las operaciones de combinar y vaciar, los monoides deben obedecer formalmente varias leyes. Para todos los valores x, y y z, en A, la combinación debe ser asociativa y el vacío debe ser un elemento de identidad:
def associativeLaw[A](x: A, y: A, z: A)
(implicit m: Monoid[A]): Boolean = {
m.combine(x, m.combine(y, z)) ==
m.combine(m.combine(x, y), z)
}
def identityLaw[A](x: A)
(implicit m: Monoid[A]): Boolean = {
(m.combine(x, m.empty) == x) &&
(m.combine(m.empty, x) == x)
}
|

Cuando definimos clases de tipo, podemos agregar anotaciones de variación al parámetro de tipo para afectar la variación de la clase de tipo y la capacidad del compilador para seleccionar instancias durante la resolución implícita.
La varianza se relaciona con los subtipos. Decimos que B es un subtipo de A si podemos usar un valor de tipo B en cualquier lugar donde esperamos un valor de tipo A.
Las anotaciones de covarianza y contravarianza surgen cuando se trabaja con constructores de tipos. Por ejemplo, denotamos la covarianza con un símbolo +:
trait F[+A] // the "+" means "covariant"
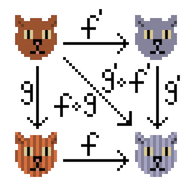
Se puede especificar exactamente qué instancia necesitamos. Sin embargo, esto no agrega valor en el código de producción. Es más simple y rápido usar las siguientes importaciones:
• import cats._ importa todas las clases de tipos de Cats de una sola vez;
• import cats.implicits._ importa todas las instancias de clase de tipo estándar y toda la sintaxis de una sola vez.
Podemos definir una instancia de Show simplemente implementando el trait :
import java.util.Date
implicit val dateShow: Show[Date] = new Show[Date] {
def show(date: Date): String = s"${date.getTime}ms since the epoch."
}
new Date().show
// res1: String = "1594650192117ms since the epoch."
Sin embargo, Cats también proporciona un par de métodos convenientes para simplificar el proceso. Hay dos métodos de construcción en el objeto complementario de Show que podemos usar para definir instancias para nuestros propios tipos:
object Show {
// Convert a function to a `Show` instance:
def show[A](f: A => String): Show[A] = ???
// Create a `Show` instance from a `toString` method:
def fromToString[A]: Show[A] = ???
}
Estos nos permiten construir instancias rápidamente con menos ceremonia que definirlas desde cero:
val implícito dateShow: Show[Date] = Show.show(date => s"${date.getTime}ms since the epoch.")
Como puede ver, el código que usa métodos de construcción es mucho más conciso que el código sin ellos. Muchas clases de tipos en Cats proporcionan métodos auxiliares como estos para construir instancias, ya sea desde cero o transformando instancias existentes para otros tipos.

Show proporciona un mecanismo para producir una salida de consola amigable para los desarrolladores sin usar toString. Aquí hay una definición abreviada:
package cats
trait Show[A] {
def show(value: A): String
}
Ahora tenemos acceso a dos instancias de Show y podemos usarlas para imprimir Ints y Strings:
val intAsString: String = showInt.show(123)
// intAsString: String = "123"
val stringAsString: String = showString.show("abc")
// stringAsString: String = "abc"

Spring Cloud generará dinámicamente una clase de proxy que se utilizará para invocar el servicio REST de destino. No se escribe ningún código para llamar al servicio que no sea una definición de interfaz.
Para habilitar el uso del cliente Feign se debe agregar una anotación, @EnableFeignClients, a la clase Application.java
Luego de habilitar el cliente de Feign, veamos una definición de interfaz de cliente de Feign que se puede usar para llama:
/*Package and import left off for conciseness*/
@FeignClient("ejemploService")
public interface EjemploFeignClient {
La gente mayor recordarán un framework que trabajaba de forma similar llamado cxf.
En la anotación @FeignClient le pasámos el nombre de la identificación del servicio que deseamos que represente la interfaz. A continuación, defimos un método, getEjemplo el cual retorna un objeto Ejemplo.
Como se puede ver la definición de la clase usa anotaciones de las cual ya estamos familiarizados.
Para usar la clase EjemploFeignClient, todo lo que necesitamos hacer es injectarla y usarla. El código de Feign Client se encargará de todo el trabajo de codificación.
Cuando utiliza la clase Spring RestTemplate estándar, todos los códigos de estado HTTP de las llamadas de servicio se devolverán a través del método getStatusCode() de la clase ResponseEntity. Con Feign Client, cualquier código de estado HTTP 4xx – 5xx devuelto por el servicio al que se llama se asignará a una FeignException. FeignException contendrá un cuerpo JSON que se puede analizar para el mensaje de error específico. Feign le brinda la capacidad de escribir una clase de decodificación de errores que asignará el error a una clase de excepción personalizada.
Dejo link : https://github.com/OpenFeign/feign

Para resolver este problema llego Raml, y veamos un ejemplo:
%RAML 1.0
title: Mobile Order API
baseUri: http://localhost:8081/api
version: 1.0
uses:
assets: assets.lib.raml
annotationTypes:
monitoringInterval:
type: integer
/orders:
displayName: Orders
get:
is: [ assets.paging ]
(monitoringInterval): 30
description: Lists all orders of a specific user
queryParameters:
userId:
type: string
description: use to query all orders of a user
post:
/{orderId}:
get:
responses:
200:
body:
application/json:
type: assets.Order
application/xml:
type: !include schemas/order.xsd
Dejo link: https://raml.org

El siguiente código muestra el método getRestTemplate() que creará el bean Spring RestTemplate respaldado por Ribbon.
package com.thoughtmechanix.licenses;
//...Most of import statements have been removed for consiceness
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
public class Application {
/*Package and import definitions left off for conciseness*/
@Component
Seguimos con el post anterior. Pero para no quedar tan colgado retomemos este código :
/*Packages and imports removed for conciseness*/
@Component
public class OrganizationDiscoveryClient {
@Autowired
private DiscoveryClient discoveryClient;
public Organization getOrganization(String organizationId) {
RestTemplate restTemplate = new RestTemplate();
List<ServiceInstance> instances = discoveryClient.getInstances("organizationservice");
if (instances.size()==0) return null;
String serviceUri = String.format("%s/v1/organizations/%s", instances.get(0).getUri().toString(),
organizationId);
ResponseEntity< Organization > restExchange = restTemplate.exchange(serviceUri,
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
}
}
Solo debemos usar Discovery-Client directamente cuando el servicio necesita consultar Ribbon para comprender qué servicios e instancias de servicio están registrados con él. Hay varios problemas con este código, incluidos los siguientes:
No se está aprovechando el balanceador de carga del lado del cliente de Ribbon: al llamar a Discovery-Client directamente, obtenemos una lista de servicios, pero tambien responsabilidad elegir qué instancias de servicio a invocar.
Se está haciendo demasiado trabajo: en este momento, debe crear la URL que se utilizará para llamar a su servicio. Es algo pequeño, pero cada pieza de código que puede evitar escribir es una pieza menos de código que tiene que depurar.
Es posible que los desarrolladores observadores de Spring hayan notado que está instanciando directamente la clase RestTemplate en el código. Esto es la antítesis de las invocaciones normales de Spring REST, ya que normalmente Spring Framework inyectaría RestTemplate en la clase que lo usa a través de la anotación @Autowired.
Ha creado una instancia de la clase RestTemplate porque una vez que haya habilitado Spring DiscoveryClient en la clase de aplicación a través de la anotación @EnableDiscovery-Client, todas las RestTemplates administradas por Spring Framework tendrán un interceptor habilitado para Ribbon. Al instanciar directamente la clase RestTemplate le permite evitar este comportamiento.
En resumen, existen mejores mecanismos para llamar a un servicio respaldado por Ribbon.
|








