Continuemos con la captura y replicación de flujos de datos.
En un entorno Streams podemos capturar los eventos de la siguiente manera: Proceso de captura o aplicación personalizada.
Los cambios de objetos de la base son escritos en el area de redologs, dado que ante un error oracle puede volver a una versión consistente y estable. Un proceso de captura es un proceso en segundo plano de Oracle que lee el registro de redolog de la base de datos para capturar los cambios de DML y DDL realizados a los objetos de la base de datos. La base de datos de origen es la base de datos donde se generó el cambio en el registro de redolog. Un proceso de captura formatea estos cambios en mensajes llamados LCR y los envía a una cola. Como un proceso de captura en ejecución captura automáticamente los cambios en función de sus reglas, la captura de cambios mediante un proceso de captura a veces se denomina captura implícita.
Hay dos tipos de LCR: una LCR de fila contiene información sobre un cambio en una fila de una tabla resultante de una operación de DML, y una LCR de DDL contiene información sobre un cambio de DDL en un objeto de base de datos. Se debe utiliza reglas para especificar qué cambios se capturan. Una sola operación DML puede cambiar más de una fila en una tabla. Por lo tanto, una sola operación DML puede generar más de una LCR de fila, y una sola transacción puede consistir en múltiples operaciones DML.
Los cambios son capturados por capture user o usuario de captura, el capture user captura todos los cambios que cumplan con el conjunto de reglas (DML o DDL)
Un proceso de captura de procesos, puede capturar cambios de una base local o de una base remota.
Downstream capture significa que un proceso de captura se ejecuta en una base de datos que no sea la base de datos de origen. Se pueden configurar de la siguiente manera :
- Una configuración Downstream capture en tiempo real, significa que los servicios de transporte redolog utilizan el log writer process (LGWR) o proceso de escritura de redolog como origen para enviar datos desde el registro de redolog en línea a la base de datos downstream. En la base de datos downstream, un proceso de servidor de archivos remoto (RFS) recibe los datos de redolog y los almacena en el registro de redolog como en espera, y el archivador en la base de datos descendente archiva los datos de redolog en el registro de redolog en espera. El proceso Downstream en tiempo real captura los cambios desde el registro de redolog en espera siempre que sea posible y desde el registro de redolog archivado siempre que sea necesario.
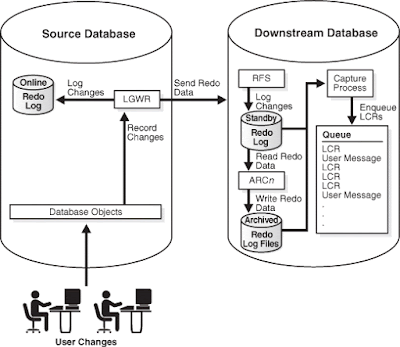
- Una configuración archived-log downstream capture, significa que los archivos de redolog archivados de la base de datos de origen se copian en la base de datos Downstream. Puede copiar los archivos de redolog archivados en la base de datos downstream utilizando los servicios de transporte de redolog, el paquete DBMS_FILE_TRANSFER, el protocolo de transferencia de archivos (FTP) o algún otro mecanismo.
Un proceso de captura Downstream en tiempo real lee el registro de redolog en espera siempre que sea posible y, de lo contrario, los redologs archivados
La otra manera de capturar datos es con una aplicación personalizada. Esta aplicacion puede capturar los datos desde los logs de transacciones, triggers o otros metodos. La aplicacion debe capturar el cambio y debe convertir este cambio a LCR y luego debe encolar este LCR en la cola de la base destino para hacer esto se pueden utilizar los paquetes DBMS_STREAMS_MESSAGING o DBMS_AQ. La aplicación debe commitiar despues de encolar los LCRs de cada transacción.
Una vez capturados los cambios debemos propagarlos.
En un entorno de replicación de Streams, los procesos de propagacion propagan los cambios capturados. Las propagaciones permiten propagar los LCR origen a las bases de datos destinos.
Las siguientes secciones describen la puesta en escena y la propagación en un entorno de replicación de Streams:
LCR Staging : Los LCR capturados se organizan en un área de preparación. En Streams, el área de preparación es una cola que puede almacenar LCR y DDL LCR, así como otros tipos de mensajes. Los LCR capturados se organizan en una cola, que es la System Global Area (SGA) asciada con una cola.
Los LCR pueden propagarse mediante una propagación o aplicarse mediante un proceso de aplicación, y un LCR Staging determinado puede propagarse y aplicarse. Una propagación en ejecución propaga automáticamente las LCR basadas en las reglas de sus conjuntos de reglas, y un proceso de aplicación en ejecución aplica LCR automáticamente .
LCR Propagation:En un entorno de replicación de Streams, una propagación normalmente propaga LCR desde una cola en la base de datos local a una cola en una base de datos remota. La cola a partir de la cual se propagan los LCR se denomina cola de origen, y la cola que recibe los LCR se denomina cola de destino. Puede haber una relación de uno a muchos, muchos a uno o muchos a muchos entre las colas de origen y destino.
Incluso después de que un LCR se propaga por una propagación o se aplica mediante un proceso de solicitud, puede permanecer en la cola de origen si también ha configurado Flujos para propagar el LCR a una o más colas diferentes. Además, observe que una cola ANYDATA puede almacenar mensajes de usuario que no sean LCR. Normalmente, los mensajes de usuario que no son de LCR se utilizan para aplicaciones de mensajería, no para la replicación.
Puede configurar un entorno de replicación de Streams para propagar LCR a través de una o más bases de datos intermedias antes de llegar a una base de datos de destino. Tal entorno de propagación se llama red dirigida. Un LCR puede o no ser procesado por un proceso de solicitud en una base de datos intermedia. Las reglas determinan qué LCR se propagan a cada base de datos de destino y puede especificar la ruta que recorrerán los LCR en su camino hacia una base de datos destino.
La ventaja de usar una red dirigida es que una base de datos de origen no necesita tener una conexión de red física con la base de datos de destino. Entonces, si desea que los LCR se propaguen de una base de datos a otra, pero no hay conexión de red directa entre las computadoras que ejecutan estas bases de datos, puede propagar los LCR sin reconfigurar su red, siempre que una o más bases de datos intermedias conecten el base de datos de origen a la base de datos de destino. Si usa redes dirigidas, y un sitio intermedio se apaga durante un período de tiempo prolongado o si se elimina, entonces es posible que necesite reconfigurar la red y el entorno de Streams.
Dejo link:
https://docs.oracle.com/cd/B19306_01/server.102/b14228/gen_rep.htm

















