miércoles, 28 de noviembre de 2018
martes, 27 de noviembre de 2018
Comparando HBase con una base de datos relacional
|
Base de datos relacional |
Apache HBase |
|
Escala de forma horizontal |
Escala de forma vertical |
|
Usa SQL para leer registros en la tabla |
Usa una API y Mapreduce para resolver las consultas |
|
Esta organizada en tablas donde cada fila tienen el mismo
numero de columnas que todas las filas de la tabla.
|
Esta organizada en tablas pero cada fila puede tener un numero
variable de columnas.
|
|
La cantidad de datos que se pueden guardar dependen de la
capacidad de un server |
La cantidad de datos que se pueden guardar dependen de la
capacidad del cluster de servidores |
|
Tiene un esquema restrictivo |
Tiene un esquema flexible |
|
Soporta ACID, es decir soporta transacciones |
No soporta ACID, no soporta transacciones |
|
Es ideal para datos estructurados |
Es ideal para datos estructurados y no estructurados.
|
|
Centralizada |
Distribuida |
|
Soporta joins |
No soporta joins |
|
Soporta integridad referencial |
No soporta integridad referencial |
|
|
|
Por lo visto son
cosas totalmente diferentes, pensadas para casos de uso diferentes.
Por lo tanto lo peor que podemos hacer es tomar un problema que se
resuelve con una base de datos relacional y tratar de utilizar HBase.
lunes, 26 de noviembre de 2018
Como es streams en Kotlin?

En Java 8 tenemos los Streams que nos permiten convertir o filtrar colecciones.
Veamos un ejemplo:
List<String> names = Arrays.asList("Joe", "Jack", "William", "Averell");
List<String> jNames = names.stream()
.filter(name -> name.startsWith("J"))
.collect(Collectors.toList());
Veamos ahora como haríamos lo mismo con Kotlin:
val names = listOf("Joe", "Jack", "William", "Averell")
val jNames = names.filter { it.startsWith("J") }
La pregunta es por que escribimos mucho menos en Kotlin. Esto es una ventaja del azúcar sintáctico + convención ante configuración. Otro temita es que kothin no es lazy como streams de java. Pero eso es tema para otro post.
domingo, 25 de noviembre de 2018
Luchando contra NullPointerException con Kotlin - parte 2

Esta es la primera parte : https://emanuelpeg.blogspot.com/2018/11/luchando-contra-nullpointerexception.html
Como habíamos dicho Kotlin tienen diferente un montón de operadores para controlar los NullPointerException.
Veamos el operador ?. Un pequeño ejemplo:
val a = "Kotlin"
val b: String? = null
println(b?.length)
println(a?.length)
Esto devuelve b.length si b no es nulo, y nulo de lo contrario, por lo tanto esto retorna un valor de tipo : Int?
Esto es muy practico, ya que nos olvidamos de hacer muchas comprobaciones por ejemplo, si necesito el nombre del profesor del curso que esta haciendo juan :
juan?.curso?.profesor?.nombre
Como no estoy seguro que juan este haciendo un curso y el curso tenga un profesor y el profesor un nombre, uso ?.
Si queremos solo valores no nulos podemos usar let :
val listWithNulls: List<String?> = listOf("Kotlin", null)
for (item in listWithNulls) {
item?.let { println(it) } // prints A and ignores null
}
let realiza la acción si no es nulo.
el operador ?. es útil para la asignación:
person?.department?.head = managersPool.getManager()
Si person o department es nulo no asigna nada.
El operador Elvis nos permite hacer acciones si los campos son nulos, veamos un ejemplo:
fun foo(node: Node): String? {
val parent = node.getParent() ?: return null
val name = node.getName() ?: throw IllegalArgumentException("name expected")
// ...
}
El operador de aserción no-nula (!!) convierte cualquier valor a un tipo que no sea nulo y lanza una excepción si el valor es nulo:
val l = b!!.length
Deberíamos manejar el NullPointerException.
Por ultimo tenemos unos chiches, por ejemplo si un valor es nulo y queremos castear nos va traer problema si este valor es null por lo tanto tenemos el as?
val aInt: Int? = a as? Int
Si tenemos una lista que permite nulos y queremos solo los valores no nulos contemos con filterNotNull :
val nullableList: List<Int?> = listOf(1, 2, null, 4)
val intList: List<Int> = nullableList.filterNotNull()
Y ya esta, que más queres?
Dejo link:
https://kotlinlang.org/docs/reference/null-safety.html
sábado, 24 de noviembre de 2018
Workshop de Laravel framework PHP
El principal objetivo del Workshop Framework PHP (Laravel) es generar un espacio de intercambio, discusión y presentación de experiencias en la temática de Framework para el desarrollo de aplicaciones Web y la tecnología Laravel que permita enriquecer los conceptos individuales de cada uno de los asistentes.
Lugar:
Facultad de Ciencia y Tecnología, Sede de Oro Verde – Ruta Provincial N° 11, Km 5 y ½. Salón de Acceso principal.
Fecha y Hora:
Viernes 30 de Noviembre de 2018, a partir de las 15:00 horas.
Agenda / Cronograma:
15:00 a 15:45 horas– Acreditaciones y armado de grupos
15:45 a 16:00 horas– Presentación del evento
16:00 a 17:00 horas– Introducción a los frameworks
17:00 a 18:00 horas– Framework Laravel
18:00 a 18:30 horas– Coffee Break
18:30 a 19:10 horas– Desafíos en laboratorio – PARTE 1
19:10 a 19:50 horas– Desafíos en laboratorio – PARTE 2
19:50 a 20:00 horas– Sorteos, entrega de premios y cierre del Evento
Inscripciones:
Costo:
El Evento es Libre y Gratuito. Los asistentes que deseen recibir una certificación de asistencia al mismo deberán abonar ($100) cien pesos al momento de matricularse.
Cabe destacar que el evento fue declarado de interés institucional por el Consejo Directivo de la Facultad de Ciencia y Tecnología de la UADER bajo la resolución número 675/2018 de fecha 13 de noviembre de 2018.

miércoles, 21 de noviembre de 2018
Luchando contra NullPointerException con Kotlin

La excepción que más se encuentra en los logs de la aplicaciones Java es NullPointerException, y esto es esperable ya que java no trae mecanismos de chequeo de nulos. Solo el if, pero es muy manual y al no ser null un objeto, se hace bastante difícil tener que checkear nulos con un if todo el tiempo.
En cambio kotlin aprendió de esto y ha implementado varios mecanismos para prevenir los NullPointerException.
El primero, no podemos asignar null a un tipo común, no compila:
var a: String = "abc"
a = null // error de compilación
Tenemos que expresamente indicar que este tipo permite nulos :
var b: String? = "abc"
b = null // ok
print(b)
Ahora bien si nosotros llamamos a un método de b y no comprobamos que no sea nulo, no funciona:
val l = b.length // error: variable 'b' can be null
Tira error de compilación. Nosotros debemos comprobar que esto no sea nulo:
val l = if (b != null) b.length else -1
Bueno, hasta aquí un primer paso, en próximo post seguimos con los operadores antinull.
domingo, 18 de noviembre de 2018
Resultados de una encuesta sobre java
Hace unos días vi los resultados que lanzo java magazine con respecto a una encuesta que hizo. Y paso a mostrar las cosas que más me llamaron la atención las que no también:
Lenguajes que se utilizan en la plataforma java, primero esta Java, luego Clojure y Kotlin :



El ORM más usado en Java es Hibernate, cantado :
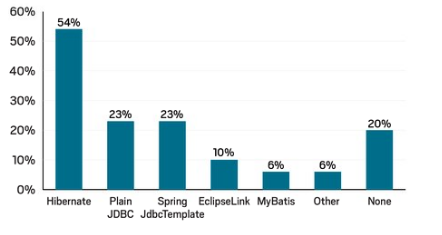



El framework para presentación más utilizado:

Dejo link: http://www.javamagazine.mozaicreader.com/NovemberDecember2018/Default/15/0#&pageSet=15&page=0&contentItem=0
Lenguajes que se utilizan en la plataforma java, primero esta Java, luego Clojure y Kotlin :
Para mi es una sorpresa no me imagine a Clojure tan usado.
Ide más usado: IntelliJ IDEA ganando por 7 puntitos a eclipse.
La base de datos más utilizada en un entorno Java es Oracle y luego MySQL :
El ORM más usado en Java es Hibernate, cantado :
El server más utilizado es Tomcat, tambien cantado:
Otra dato que me pareció cantado, es el lenguaje que se utiliza en entorno Java (que no es propio de este entorno) : javascript y sql pero me llamo la atención que aparezca Python, C, C#, Go, etc
La herramienta para la gestión y construcción de proyectos Java :
El framework para presentación más utilizado:
Dejo link: http://www.javamagazine.mozaicreader.com/NovemberDecember2018/Default/15/0#&pageSet=15&page=0&contentItem=0
sábado, 17 de noviembre de 2018
5 cursos de TensorFlow

Si queremos aprender una tecnología nueva lo mejor es empezar por un libro o un curso y luego ir a tutoriales de internet. Saltar de tutorial en tutorial, nos da el conocimiento pero nos falta el orden. Con un curso o un libro aprendemos ordenadamente, como debe ser.
Por lo tanto dejo 5 cursos de TensorFlow :
- Complete Guide to TensorFlow for Deep Learning with Python
- Machine Learning with TensorFlow + Real-Life Business Case
- TensorFlow: Getting Started
- Detect Fraud and Predict the Stock Market with TensorFlow
- A beginners guide for building neural networks in TensorFlow
miércoles, 14 de noviembre de 2018
Extension functions en Kotlin

Es decir puedo tomar una lista o un String o un Entero o la clase que sea y agregarle un método, veamos un ejemplo con String :
fun String.removeFirstLastChar(): String = this.substring(1, this.length - 1)
Entonces ahora String tendrá un nuevo método, y lo llamamos de esta manera:
fun main(args: Array<String>) {
val myString= "Hello Everyone"
val result = myString.removeFirstLastChar()
println("First character is: $result")
}
Si queremos aprovechar estas extensiones solo tenemos que importar el .java donde se programaron las extensiones. Y de esta manera nos ahorramos de tener clases Utils que agregan funcionalidad a clases del sdk.
martes, 13 de noviembre de 2018
Apache HBase vs HDFS

Apache HBase esta
ligada directamente con Hadoop, dado que funciona sobre el sistema de
archivos HDFS. Dada esta relación HBase utiliza todas las ventajas y
características de Hadoop. Es tolerante a fallos, utiliza
map-reduce, distribuido, escala de forma horizontal, etc, etc.
Pero que ventajas tiene utilizar Apache HBase comparado con utilizar HDFS solo:
Hadoop/HDFS
|
HBase
|
| Provee un file system distribuido. | Provee un almacén de datos basado en columnas |
| Está optimizado para el almacenamiento de archivos de gran tamaño sin lectura/escritura aleatoria de estos archivos | Esto está optimizado para datos tabulares con facilidad de lectura/escritura aleatoria |
| Utiliza archivos planos. | Usa pares de datos clave-valor |
| El modelo de datos no es flexible. | Esto utiliza almacenamiento tabular con soporte incorporado de Hadoop MapReduce |
| Está principalmente optimizado para escritura de una sola lectura | Está optimizado para leer/escribir muchas veces |
domingo, 11 de noviembre de 2018
Como se organiza una base Apache HBase?

Una tabla Apache HBase esta compuesta de filas, familia de columnas, columnas y celdas. La clave de fila es única e identifica a la fila, familia de columnas son un grupo de columnas, la columna es un campo de la fila y la celda es el valor que tiene esa fila en esa columna determinada.
Características de Apache HBase

Apache HBase como habrán leído anteriormente es una base NoSql, la cual es orientada a columna.
Pero que características la hacen una base tan especial:
- Balanceador de carga y recuperación de errores automático: HBase corre sobre el sistema de archivos de Hadoop, hdfs, el cual puede recuperarse dado a que cuenta con bloques de recuperación y servidores de replicación.
- Fragmentación automática: HBase maneja el concepto de región lo que permite tener replicaciones en una región determinada y compartir la información con dicha región.
- Integración con Hadoop: HBase corre sobre el sistema de archivos de Hadoop, por lo que cuenta con una muy buena integración con el ecosistema Hadoop.
- Map-reduce: HBase utiliza Hadoop map-reduce framework para resolver problemas en paralelo.
- Java Api: los clientes java pueden utilizar toda la potencia de la jdk, ya que hbase fue escrito en java.
- Thrift o rest web services: HBase brinda 2 caminos para exponer funcionalidad una REST API o servicios Thrift
- Soporta monitoreo: Igual que Hadoop, soporta software de monitoreo el cual nos indicara la salud de nuestra base de datos.
- Distribuida: Puede correr en varios servers.
- Escalabilidad lineal: es decir que podemos prever que va a crecer su performance agragando un servidor o cuanto cae si quitamos un servidor.
- Orientado a Columna: esto no es una ventaja es solo una característica. Pero quería hacer la lista larga.
- Soporta comandos de shell: Se puede administrar HBase totalmente desde una consola .
- Soporta versiones: soporta diferentes versiones, a la vez permite hacer snapshot, de versiones anteriores. A la vez soporta multilples versiones de un solo registro por medio de la snapshot que utiliza internamente
jueves, 8 de noviembre de 2018
Que viene en Java 12?

Ya tenemos Java 11 en el mercado, por lo tanto es hora de pensar en java 12 y estas son las nuevas características :
Un switch más inteligente: En java 12 vamos a poder hacer lo siguiente:
switch (day) {
case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);
case TUESDAY -> System.out.println(7);
case THURSDAY, SATURDAY -> System.out.println(8);
case WEDNESDAY -> System.out.println(9);
}
A la vez vamos a poder asignar un elemento de la siguiente manera:
int numLetters = switch (day) {
case MONDAY, FRIDAY, SUNDAY -> 6;
case TUESDAY -> 7;
case THURSDAY, SATURDAY -> 8;
case WEDNESDAY -> 9;
};
o podríamos hacer algo así:
int j = switch (day) {
case MONDAY -> 0;
case TUESDAY -> 1;
default -> {
int k = day.toString().length();
int result = f(k);
break result;
}
};
También va traer literales Raw String, que que seria? Podemos tener string en varias lineas:
String html = `<html>
<body>
<p>Hello World.</p>
</body>
</html>
`;
veamos otro ejemplo:
String script = `function hello() {
print('"Hello World"');
}
hello();
`;
Este string no solo permite varias líneas sino que tambien no es necesario el carácter de escape, para caracteres raros.
Y luego tenemos algunos cambios menores.
Estos cambios están en draft pero que piensa de ellos.
miércoles, 7 de noviembre de 2018
10 cursos gratuitos de Java para principiantes y programadores experimentados.

Por lo tanto dejo 10 cursos gratuitos de Java para principiantes y programadores experimentados :
- Java Programming for Complete Beginners in 250 Steps
- Java Tutorial for Complete Beginners
- Java Multithreading
- Practice Java by Building Projects
- Java Database Connection: JDBC and MySQL
- Java for Absolute Beginners
- Eclipse IDE for Beginners: Increase Your Java Productivity
- Java 9 New Features In Simple Way - Overview
- Java Programming Basics
- HANDS ON DOCKER for JAVA Developers
domingo, 4 de noviembre de 2018
java.util.stream en Java 8

Permite junto con expresiones Lambda crear una composición de operaciones que se aplican a las colecciones. Un estilo Linq de .net pero en Java.
El procesamiento de los elementos de una colección se hace de forma declarativa. Permite manipular, realizar búsquedas y realizar conversiones en sets de datos grandes de forma eficiente.
Se componen operaciones al estilo SQL y admiten operaciones comúnmente utilizadas:
filter map, reduce, find, match, sorted…
Los patrones de procesamiento de colecciones típicos son similares a las operaciones del estilo de las que se usan en SQL para "buscar" (por ejemplo, buscar la transacción de mayor valor) o "agrupar" (por ejemplo, agrupar todas las transacciones relacionadas con compras de almacén). La mayoría de las bases de datos permiten establecer operaciones como esas de manera declarativa. Por ejemplo, la siguiente consulta de SQL permite buscar la identificación de la transacción de mayor valor: "SELECT id, MAX(value) from transactions".
Veamos un ejemplo para tener una idea del nuevo estilo de programación que posibilitan los streams de Java SE 8. Imaginemos que necesitamos encontrar todas las transacciones del tipo grocery y obtener un listado de identificaciones de transacciones ordenadas de mayor a menor por valor de transacción. En Java SE 7, usaríamos el código que se muestra aquí:
List<Transaction> groceryTransactions = new Arraylist<>();
for(Transaction t: transactions){
if(t.getType() == Transaction.GROCERY){
groceryTransactions.add(t);
}
}
Collections.sort(groceryTransactions, new Comparator(){
public int compare(Transaction t1, Transaction t2){
return t2.getValue().compareTo(t1.getValue());
}
});
List<Integer> transactionIds = new ArrayList<>();
for(Transaction t: groceryTransactions){
transactionsIds.add(t.getId());
}
En Java SE 8, usaremos este código :
List<Integer> transactionsIds = transactions.stream()
.filter(t -> t.getType() == Transaction.GROCERY)
.sorted(comparing(Transaction::getValue).reversed())
.map(Transaction::getId)
.collect(toList());
Un stream es como una abstracción para expresar operaciones eficientes al estilo SQL con relación a una colección de datos. Además, esas operaciones pueden parametrizarse sucintamente mediante expresiones lambda.
Además en Java SE 8 es fácil usar tareas en paralelo solo es necesario reemplazar la instrucción stream() por parallel Stream(), y la API de streams descompondrá internamente la consulta para aprovechar los núcleos múltiples de la computadora.
List<Integer> transactionsIds =
transactions.parallelStream()
.filter(t -> t.getType() == Transaction.GROCERY)
.sorted(comparing(Transaction::getValue).reversed())
.map(Transaction::getId)
.collect(toList());
Podemos entender un stream como una abstracción para expresar operaciones eficientes al estilo SQL con relación a una colección de datos. Además, esas operaciones pueden parametrizarse sucintamente mediante expresiones lambda.
Otra cosa importante es que stream es lazy es decir, no se ejecuta hasta que llamamos al metodo collect.
Dejo link: https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
List<Integer> transactionsIds =
transactions.parallelStream()
.filter(t -> t.getType() == Transaction.GROCERY)
.sorted(comparing(Transaction::getValue).reversed())
.map(Transaction::getId)
.collect(toList());
Podemos entender un stream como una abstracción para expresar operaciones eficientes al estilo SQL con relación a una colección de datos. Además, esas operaciones pueden parametrizarse sucintamente mediante expresiones lambda.
Otra cosa importante es que stream es lazy es decir, no se ejecuta hasta que llamamos al metodo collect.
Dejo link: https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
sábado, 3 de noviembre de 2018
Libros gratuidos de javacodegeeks
| |||||||||||||||||||||
|




Suscribirse a:
Comentarios (Atom)
