El almacén de datos más simple con el que querrías trabajar podría ser una matriz o una lista. Se vería como la siguiente figura:
Si se persiste en esta lista, podría consultarla más adelante, pero tendría que examinar cada valor para saber qué representaba, o almacenar siempre cada valor en el mismo lugar de la lista y luego mantener externamente la documentación sobre qué se encuentra en que celda. Eso significa que podría tener que proporcionar valores de marcador de posición vacíos (nulos) para mantener el tamaño predeterminado de la matriz en caso de que no tuviera un valor para un atributo opcional (como un número de fax o un número de apartamento). Una matriz es una estructura de datos claramente útil, pero no semánticamente rica.
Así que nos gustaría agregar una segunda dimensión a esta lista: nombres para que coincidan con los valores. Daremos nombres a cada celda, y ahora tenemos una estructura de mapa, como se muestra en la siguiente figura:
Esto es una mejora porque podemos saber los nombres de nuestros valores. Entonces, si decidimos que nuestro mapa contendría la información del usuario, podríamos tener nombres de columna como primer nombre, último nombre, teléfono, correo electrónico, etc. Esta es una estructura algo más rica para trabajar.
Pero la estructura que hemos construido hasta ahora solo funciona si tenemos una instancia de una entidad determinada, como una sola persona, usuario, hotel o tweet. No nos da mucho si queremos almacenar varias entidades con la misma estructura, que es ciertamente lo que queremos hacer. No hay nada para unificar una colección de pares de nombre / valor, y no hay manera de repetir los mismos nombres de columna. Así que necesitamos algo que agrupará algunos de los valores de columna en un grupo claramente direccionable. Necesitamos una clave para hacer referencia a un grupo de columnas que deben tratarse juntas como un conjunto. Necesitamos filas. Luego, si obtenemos una sola fila, podemos obtener todos los pares de nombre / valor para una sola entidad a la vez, o simplemente obtener los valores de los nombres que nos interesan. Podríamos llamar a estas columnas de pares de nombre / valor. Podríamos llamar a cada entidad separada que contiene un conjunto de filas de columnas.
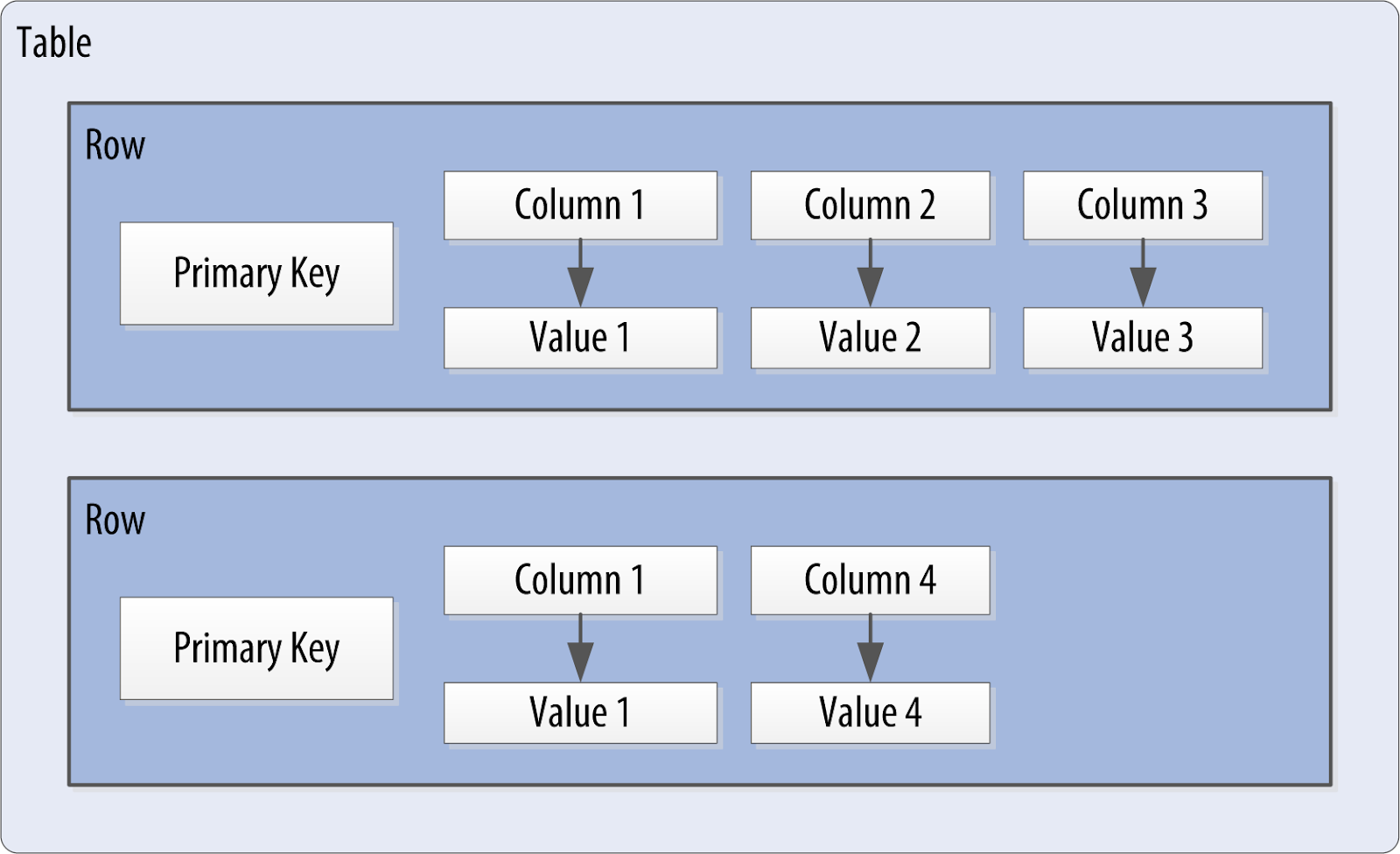
Y el identificador único para cada fila podría llamarse clave de fila o clave principal.
La siguinte figura muestra el contenido de una fila simple: una clave principal, que es en sí misma una o más columnas, y columnas adicionales.
Cassandra define una tabla como una división lógica que asocia datos similares. Por ejemplo, podríamos tener una tabla de usuario, una tabla de hotel, una tabla de libreta de direcciones, etc. De esta manera, una tabla de Cassandra es análoga a una tabla en el mundo relacional.
Ahora no necesitamos almacenar un valor para cada columna cada vez que almacenamos una nueva entidad. Quizás no sepamos los valores de cada columna para una entidad dada. Por ejemplo, algunas personas tienen un segundo número de teléfono y otras no, y en lugar de almacenar el valor nulo para aquellos valores que no conocemos, lo que desperdiciaría espacio, simplemente no almacenaremos esa columna para esa fila. Así que ahora tenemos una estructura de matriz multidimensional dispersa que se parece a la siñguiente figura :

Al diseñar una tabla en una base de datos relacional tradicional, normalmente se trata de "entidades" o del conjunto de atributos que describen un nombre particular (hotel, usuario, producto, etc.). No se piensa mucho en el tamaño de las filas en sí, porque el tamaño de la fila no es negociable una vez que haya decidido qué sustantivo representa su tabla. Sin embargo, cuando trabajas con Cassandra, realmente tienes que tomar una decisión sobre el tamaño de tus filas: pueden ser anchas o delgadas, dependiendo del número de columnas que contenga la fila.
Una fila ancha significa una fila que tiene muchos y muchos (quizás decenas de miles o incluso millones) de columnas. Normalmente, hay un número menor de filas que van junto con tantas columnas. A la inversa, podría tener algo más cercano a un modelo relacional, donde define un número menor de columnas y usa muchas filas diferentes, es decir, el modelo delgado.
En Cassandra, tenemos estas estructuras de datos básicas :
- La columna, que es un par de nombre / valor
- La fila, que es un contenedor para columnas referenciadas por una clave primaria
- La tabla, que es un contenedor para filas.
- El keyspace, que es un contenedor para tablas.
- El clúster, que es un contenedor para espacios de claves que abarca uno o más nodos
Así que ese es el enfoque de abajo hacia arriba para mirar el modelo de datos de Cassandra. Ahora que conocemos la terminología básica, examinemos cada estructura con más detalle en proximos posts.