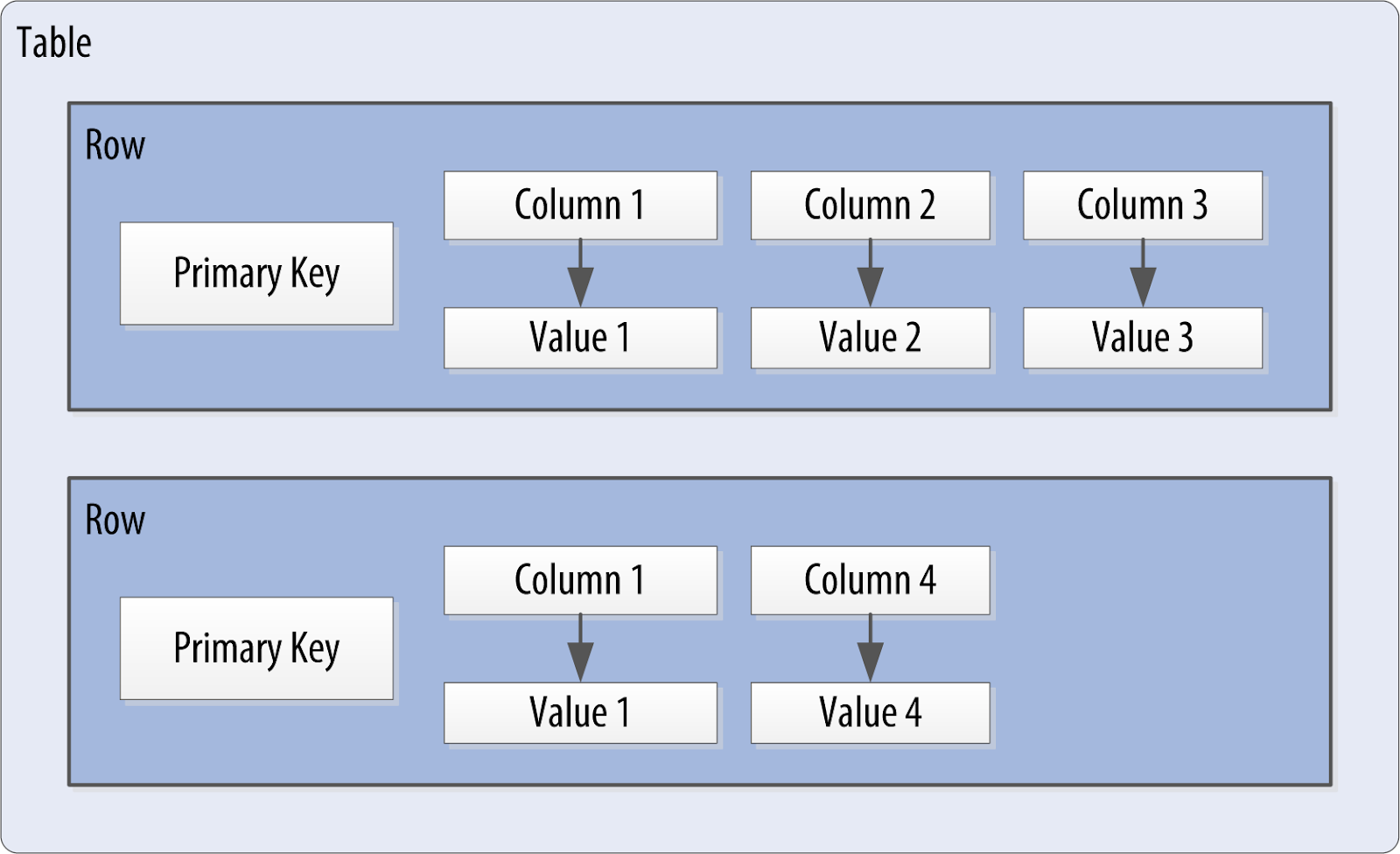
Una columna es la unidad más básica de la estructura de datos en el modelo de datos de Cassandra. Hasta ahora hemos visto que una columna contiene un nombre y un valor. Restringimos cada uno de los valores para que sean de un tipo particular cuando definimos la columna. Vamos profundizar en los diversos tipos que están disponibles para cada columna, pero primero echemos un vistazo a algunos otros atributos de una columna que aún no hemos discutido: marcas de tiempo y tiempo de vida. Estos atributos son clave para entender cómo Cassandra usa el tiempo para mantener los datos actualizados.
Marcas de tiempo: Cada vez que escribe datos en Cassandra, se genera una marca de tiempo para cada valor de columna que se actualiza. Internamente, Cassandra usa estas marcas de tiempo para resolver cualquier cambio conflictivo que se realice en el mismo valor. Generalmente, la última marca de tiempo gana.
Veamos las marcas de tiempo que se generaron para nuestras escrituras anteriores agregando la función writetime() a nuestro comando SELECT. Haremos esto en la columna de apellido e incluiremos un par de otros valores para el contexto:
cqlsh:my_keyspace> SELECT first_name, last_name, writetime(last_name) FROM user;
first_name | last_name | writetime(last_name)
------------+-------------+----------------------
Mary | Rodriguez | 1434591198790252
Bill | Nguyen | 1434591198798235
(2 rows)
Podríamos esperar que si solicitamos la marca de tiempo en first_name obtendríamos un resultado similar. Sin embargo, resulta que Cassandra no nos permite solicitar la marca de tiempo en las columnas de clave principal:
cqlsh:my_keyspace> SELECT WRITETIME(first_name) FROM user;
InvalidRequest: code=2200 [Invalid query] message="Cannot use selection function writeTime on PRIMARY KEY part first_name"
Cassandra también nos permite especificar una marca de tiempo cuando modificamos. Usaremos la opción USING TIMESTAMP para establecer manualmente una marca de tiempo (tenga en cuenta que la marca de tiempo debe ser posterior a la de nuestro comando SELECT, o se ignorará la ACTUALIZACIÓN):
cqlsh:my_keyspace> UPDATE user USING TIMESTAMP 1434373756626000 SET last_name = 'Boateng' WHERE first_name = 'Mary' ;
cqlsh:my_keyspace> SELECT first_name, last_name, WRITETIME(last_name) FROM user WHERE first_name = 'Mary';
first_name | last_name | writetime(last_name)
------------+-------------+---------------------
Mary | Boateng | 1434373756626000
(1 rows)
Esta declaración tiene el efecto de agregar la columna de apellido a la fila identificada por la clave principal "Mary", y establecer la marca de tiempo al valor que proporcionamos.