|
miércoles, 12 de junio de 2019
Libro Java Code Geeks




Apache Dumbo

Apache Software Foundation anunció recientemente que Apache Dubbo es un proyecto Top level. Apache Dubbo es framework RPC de código abierto basado en Java. Originalmente fue desarrollado en Alibaba, fue de código abierto en 2011 e ingresó a la Incubadora de Apache en febrero de 2018. Dubbo trae funcionalidades clave como llamadas remotas basadas en interfaz, tolerancia a fallas y balanceo de carga, y registro y descubrimiento automáticos de servicios.
Veamos como funciona:

- Container es responsable de iniciar, cargar y ejecutar el proveedor de servicios
- Provider registra sus servicios en el Register durante su inicialización.
- Consumer suscribe los servicios que necesita en el Register cuando comienza
- Register devuelve la lista de Providers a los Consumer y, cuando se produce un cambio, el Register envía los datos modificados al Consumer
- Sobre la base de un algoritmo de equilibrio de carga flexible, el Consumer seleccionará uno de los Provider y ejecutará la invocación, seleccionará automáticamente otro Provider cuando ocurra una falla.
- Tanto el Consumer como el Provider contarán las invocaciones de servicio y el tiempo que lleva en la memoria, y enviarán las estadísticas a Monitorear cada minuto.
Las características de Apache Dubbo incluyen:
- Una interfaz transparente basada en RPC.
- Balanceo de carga inteligente, que soporta múltiples estrategias de balanceo de carga listas para usar
- Registro de servicio automático y descubrimiento.
- Alta extensibilidad, diseño de micro-kernel y plugin que asegura que puede ser fácilmente extendido por la implementación de terceros a través de características principales como protocolo, transporte y serialización.
- Enrutamiento del tráfico en tiempo de ejecución, que se puede configurar en tiempo de ejecución para que el tráfico se pueda enrutar de acuerdo con diferentes reglas, lo que facilita la compatibilidad con características como la implementación azul-verde, el enrutamiento que reconoce el centro de datos, etc.
- Gobierno visualizado del servicio, que proporciona herramientas completas para el gobierno y el mantenimiento del servicio, como la consulta de metadatos del servicio, el estado de mantenimiento y las estadísticas
Para comenzar a usar Dubbo, primero agregue la dependencia de Maven:
<dependencies>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>2.7.2<</version>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-zookeeper</artifactId>
<version>2.7.2<</version>
<type>pom</type>
</dependency>
</dependencies>
domingo, 9 de junio de 2019
Columnas en Apache Cassandra

Una columna es la unidad más básica de la estructura de datos en el modelo de datos de Cassandra. Hasta ahora hemos visto que una columna contiene un nombre y un valor. Restringimos cada uno de los valores para que sean de un tipo particular cuando definimos la columna. Vamos profundizar en los diversos tipos que están disponibles para cada columna, pero primero echemos un vistazo a algunos otros atributos de una columna que aún no hemos discutido: marcas de tiempo y tiempo de vida. Estos atributos son clave para entender cómo Cassandra usa el tiempo para mantener los datos actualizados.
Marcas de tiempo: Cada vez que escribe datos en Cassandra, se genera una marca de tiempo para cada valor de columna que se actualiza. Internamente, Cassandra usa estas marcas de tiempo para resolver cualquier cambio conflictivo que se realice en el mismo valor. Generalmente, la última marca de tiempo gana.
Veamos las marcas de tiempo que se generaron para nuestras escrituras anteriores agregando la función writetime() a nuestro comando SELECT. Haremos esto en la columna de apellido e incluiremos un par de otros valores para el contexto:
cqlsh:my_keyspace> SELECT first_name, last_name, writetime(last_name) FROM user;
first_name | last_name | writetime(last_name)
------------+-------------+----------------------
Mary | Rodriguez | 1434591198790252
Bill | Nguyen | 1434591198798235
(2 rows)
Podríamos esperar que si solicitamos la marca de tiempo en first_name obtendríamos un resultado similar. Sin embargo, resulta que Cassandra no nos permite solicitar la marca de tiempo en las columnas de clave principal:
cqlsh:my_keyspace> SELECT WRITETIME(first_name) FROM user;
InvalidRequest: code=2200 [Invalid query] message="Cannot use selection function writeTime on PRIMARY KEY part first_name"
Cassandra también nos permite especificar una marca de tiempo cuando modificamos. Usaremos la opción USING TIMESTAMP para establecer manualmente una marca de tiempo (tenga en cuenta que la marca de tiempo debe ser posterior a la de nuestro comando SELECT, o se ignorará la ACTUALIZACIÓN):
cqlsh:my_keyspace> UPDATE user USING TIMESTAMP 1434373756626000 SET last_name = 'Boateng' WHERE first_name = 'Mary' ;
cqlsh:my_keyspace> SELECT first_name, last_name, WRITETIME(last_name) FROM user WHERE first_name = 'Mary';
first_name | last_name | writetime(last_name)
------------+-------------+---------------------
Mary | Boateng | 1434373756626000
(1 rows)
Esta declaración tiene el efecto de agregar la columna de apellido a la fila identificada por la clave principal "Mary", y establecer la marca de tiempo al valor que proporcionamos.
sábado, 8 de junio de 2019
Apache Ambari

Ambari es utilizado por compañías como IBM, Hortonworks, Cardinal Health, EBay, Expedia, Kayak.com, club de préstamos, Neustar, Macy's, Pandora Radio, Samsung, Shutterfly y Spotify.
Apache Ambari, como parte de la plataforma de datos Hortonworks, permite que las empresas planifiquen, instalen y configuren de manera segura HDP, lo que facilita el mantenimiento y la administración continua del clúster, sin importar el tamaño del clúster.
HDP sanbox es una imagen de los productos de apache que se utilizan en la distribución de HortonWorks y permite administrar todo el software con ambari, de forma muy fácil.
Ambari actualmente soporta 64-bit y corre sobre los siguientes sistemas operativos :
- RHEL (Redhat Enterprise Linux) 7.4, 7.3, 7.2
- CentOS 7.4, 7.3, 7.2
- OEL (Oracle Enterprise Linux) 7.4, 7.3, 7.2
- Amazon Linux 2
- SLES (SuSE Linux Enterprise Server) 12 SP3, 12 SP2
- Ubuntu 14 and 16
- Debian 9
Les dejo un video :
https://ambari.apache.org/
https://es.hortonworks.com/apache/ambari/
https://en.wikipedia.org/wiki/Apache_Ambari
viernes, 7 de junio de 2019
Cloud data warehousing for Dummies

Otro libro gratuito!!
Esta guía explica data warehousing en la nube y cómo se compara con otras plataformas de datos.
Incluyen:
- Qué es un data warehousing de datos en la nube.
- Tendencias que provocaron la adopción del almacenamiento de datos en la nube.
- Cómo el almacén de datos en la nube se compara con las ofertas tradicionales y noSQL
- Cómo evaluar diferentes soluciones de almacenamiento de datos en la nube.
- Consejos para elegir un almacén de datos en la nube
Data as a feature
Recibí un mail de O'reilly sobre un libro gratuito y bueno, quiero compartirlo :
|


jueves, 6 de junio de 2019
Tablas en Cassandra
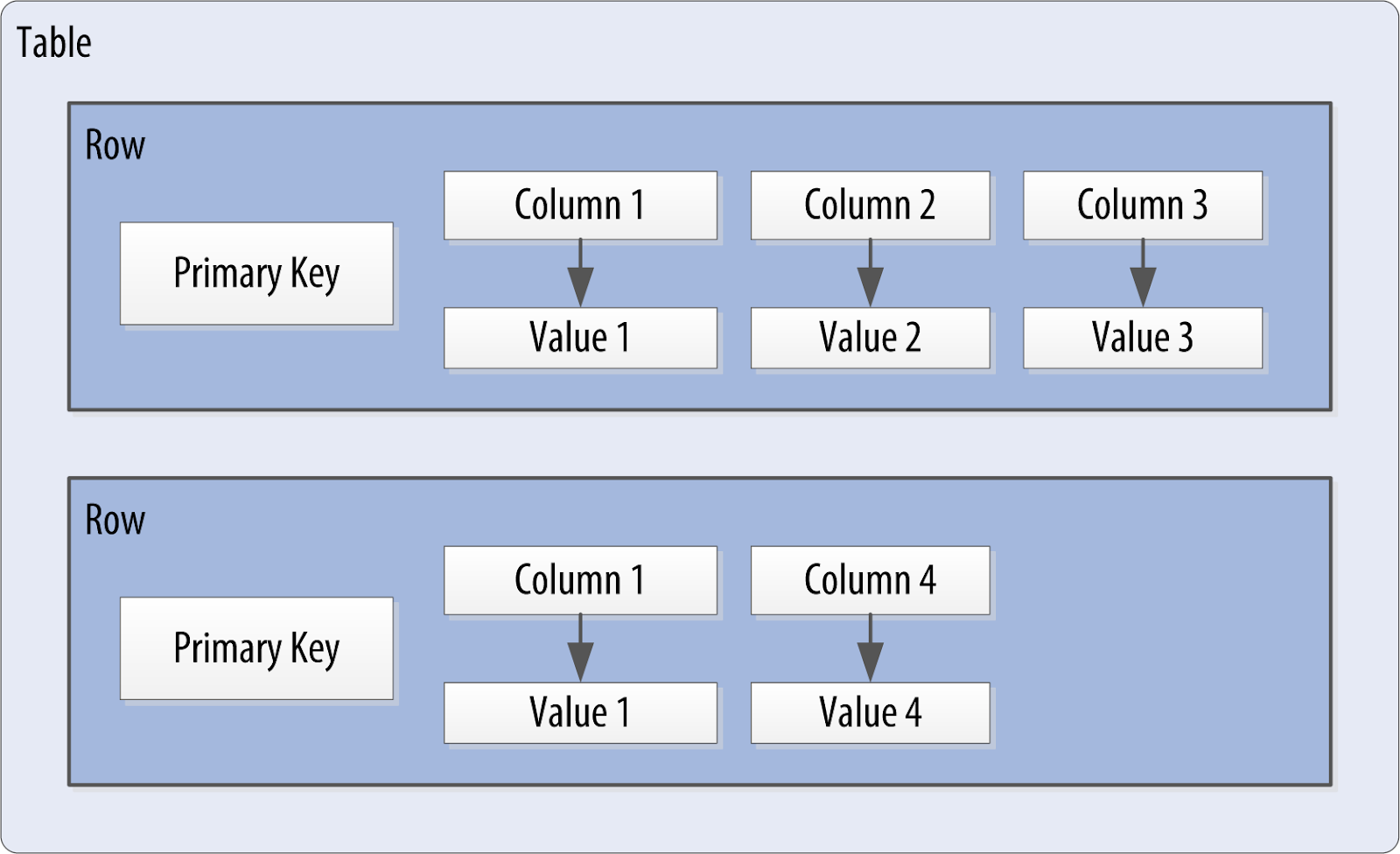
Una tabla es un contenedor para una colección ordenada de filas, cada una de las cuales es una colección ordenada de columnas. El orden está determinado por las columnas, que se identifican como claves. Pronto veremos cómo Cassandra usa claves adicionales más allá de la clave principal.
Cuando escribe datos en una tabla en Cassandra, especifica valores para una o más columnas. Esa colección de valores se llama una fila. Al menos uno de los valores que especifique debe ser una clave principal que sirva como identificador único para esa fila.
Leemos usando el comando SELECT en cqlsh:
cqlsh:my_keyspace> SELECT * FROM user WHERE first_name='Bill';
first_name | last_name
------------+-----------
Bill | Nguyen
(1 rows)
Notarás en la última fila que el shell nos dice que se devolvió una fila. Resulta ser la fila identificada por el primer nombre "Bill". Esta es la clave principal que identifica esta fila.
No necesitamos incluir un valor para cada columna cuando agregamos una nueva fila a la tabla. Probemos esto con nuestra tabla de usuarios usando el comando ALTER TABLE y luego veamos los resultados usando el comando DESCRIBE TABLE:
cqlsh:my_keyspace> ALTER TABLE user ADD title text;
cqlsh:my_keyspace> DESCRIBE TABLE user;
CREATE TABLE my_keyspace.user (
first_name text PRIMARY KEY,
last_name text,
title text
) ...
Vemos que se ha añadido la columna de título. Tenga en cuenta que hemos acortado la salida para omitir las diversas configuraciones de la tabla.
Ahora, escribamos un par de filas, llenemos diferentes columnas para cada una y veamos los resultados:
cqlsh:my_keyspace> INSERT INTO user (first_name, last_name, title)
VALUES ('Bill', 'Nguyen', 'Mr.');
cqlsh:my_keyspace> INSERT INTO user (first_name, last_name) VALUES
('Mary', 'Rodriguez');
cqlsh:my_keyspace> SELECT * FROM user;
first_name | last_name | title
------------+-----------+-------
Mary | Rodriguez | null
Bill | Nguyen | Mr.
(2 rows)
Ahora que hemos aprendido más sobre la estructura de una tabla y hemos realizado algunos modelos de datos, profundicemos en las columnas.
domingo, 2 de junio de 2019
Clusters y Keyspaces en Cassandra

Keyspaces: Un clúster es un contenedor para keyspaces. Un keyspace es un contenedor más externo para datos en Cassandra, que se corresponde estrechamente con una base de datos relacional. De la misma manera que una base de datos es un contenedor para tablas en el modelo relacional, un keyspace es un contenedor para tablas en el modelo de datos de Cassandra. Al igual que una base de datos relacional, un keyspace tiene un nombre y un conjunto de atributos que definen el comportamiento de todo el keyspace.
Modelo de datos en Cassandra
El almacén de datos más simple con el que querrías trabajar podría ser una matriz o una lista. Se vería como la siguiente figura:

Si se persiste en esta lista, podría consultarla más adelante, pero tendría que examinar cada valor para saber qué representaba, o almacenar siempre cada valor en el mismo lugar de la lista y luego mantener externamente la documentación sobre qué se encuentra en que celda. Eso significa que podría tener que proporcionar valores de marcador de posición vacíos (nulos) para mantener el tamaño predeterminado de la matriz en caso de que no tuviera un valor para un atributo opcional (como un número de fax o un número de apartamento). Una matriz es una estructura de datos claramente útil, pero no semánticamente rica.
Así que nos gustaría agregar una segunda dimensión a esta lista: nombres para que coincidan con los valores. Daremos nombres a cada celda, y ahora tenemos una estructura de mapa, como se muestra en la siguiente figura:

Esto es una mejora porque podemos saber los nombres de nuestros valores. Entonces, si decidimos que nuestro mapa contendría la información del usuario, podríamos tener nombres de columna como primer nombre, último nombre, teléfono, correo electrónico, etc. Esta es una estructura algo más rica para trabajar.
Pero la estructura que hemos construido hasta ahora solo funciona si tenemos una instancia de una entidad determinada, como una sola persona, usuario, hotel o tweet. No nos da mucho si queremos almacenar varias entidades con la misma estructura, que es ciertamente lo que queremos hacer. No hay nada para unificar una colección de pares de nombre / valor, y no hay manera de repetir los mismos nombres de columna. Así que necesitamos algo que agrupará algunos de los valores de columna en un grupo claramente direccionable. Necesitamos una clave para hacer referencia a un grupo de columnas que deben tratarse juntas como un conjunto. Necesitamos filas. Luego, si obtenemos una sola fila, podemos obtener todos los pares de nombre / valor para una sola entidad a la vez, o simplemente obtener los valores de los nombres que nos interesan. Podríamos llamar a estas columnas de pares de nombre / valor. Podríamos llamar a cada entidad separada que contiene un conjunto de filas de columnas.
Y el identificador único para cada fila podría llamarse clave de fila o clave principal.
La siguinte figura muestra el contenido de una fila simple: una clave principal, que es en sí misma una o más columnas, y columnas adicionales.

Cassandra define una tabla como una división lógica que asocia datos similares. Por ejemplo, podríamos tener una tabla de usuario, una tabla de hotel, una tabla de libreta de direcciones, etc. De esta manera, una tabla de Cassandra es análoga a una tabla en el mundo relacional.
Ahora no necesitamos almacenar un valor para cada columna cada vez que almacenamos una nueva entidad. Quizás no sepamos los valores de cada columna para una entidad dada. Por ejemplo, algunas personas tienen un segundo número de teléfono y otras no, y en lugar de almacenar el valor nulo para aquellos valores que no conocemos, lo que desperdiciaría espacio, simplemente no almacenaremos esa columna para esa fila. Así que ahora tenemos una estructura de matriz multidimensional dispersa que se parece a la siñguiente figura :

Al diseñar una tabla en una base de datos relacional tradicional, normalmente se trata de "entidades" o del conjunto de atributos que describen un nombre particular (hotel, usuario, producto, etc.). No se piensa mucho en el tamaño de las filas en sí, porque el tamaño de la fila no es negociable una vez que haya decidido qué sustantivo representa su tabla. Sin embargo, cuando trabajas con Cassandra, realmente tienes que tomar una decisión sobre el tamaño de tus filas: pueden ser anchas o delgadas, dependiendo del número de columnas que contenga la fila.
Una fila ancha significa una fila que tiene muchos y muchos (quizás decenas de miles o incluso millones) de columnas. Normalmente, hay un número menor de filas que van junto con tantas columnas. A la inversa, podría tener algo más cercano a un modelo relacional, donde define un número menor de columnas y usa muchas filas diferentes, es decir, el modelo delgado.
En Cassandra, tenemos estas estructuras de datos básicas :

Si se persiste en esta lista, podría consultarla más adelante, pero tendría que examinar cada valor para saber qué representaba, o almacenar siempre cada valor en el mismo lugar de la lista y luego mantener externamente la documentación sobre qué se encuentra en que celda. Eso significa que podría tener que proporcionar valores de marcador de posición vacíos (nulos) para mantener el tamaño predeterminado de la matriz en caso de que no tuviera un valor para un atributo opcional (como un número de fax o un número de apartamento). Una matriz es una estructura de datos claramente útil, pero no semánticamente rica.
Así que nos gustaría agregar una segunda dimensión a esta lista: nombres para que coincidan con los valores. Daremos nombres a cada celda, y ahora tenemos una estructura de mapa, como se muestra en la siguiente figura:

Esto es una mejora porque podemos saber los nombres de nuestros valores. Entonces, si decidimos que nuestro mapa contendría la información del usuario, podríamos tener nombres de columna como primer nombre, último nombre, teléfono, correo electrónico, etc. Esta es una estructura algo más rica para trabajar.
Pero la estructura que hemos construido hasta ahora solo funciona si tenemos una instancia de una entidad determinada, como una sola persona, usuario, hotel o tweet. No nos da mucho si queremos almacenar varias entidades con la misma estructura, que es ciertamente lo que queremos hacer. No hay nada para unificar una colección de pares de nombre / valor, y no hay manera de repetir los mismos nombres de columna. Así que necesitamos algo que agrupará algunos de los valores de columna en un grupo claramente direccionable. Necesitamos una clave para hacer referencia a un grupo de columnas que deben tratarse juntas como un conjunto. Necesitamos filas. Luego, si obtenemos una sola fila, podemos obtener todos los pares de nombre / valor para una sola entidad a la vez, o simplemente obtener los valores de los nombres que nos interesan. Podríamos llamar a estas columnas de pares de nombre / valor. Podríamos llamar a cada entidad separada que contiene un conjunto de filas de columnas.
Y el identificador único para cada fila podría llamarse clave de fila o clave principal.
La siguinte figura muestra el contenido de una fila simple: una clave principal, que es en sí misma una o más columnas, y columnas adicionales.

Cassandra define una tabla como una división lógica que asocia datos similares. Por ejemplo, podríamos tener una tabla de usuario, una tabla de hotel, una tabla de libreta de direcciones, etc. De esta manera, una tabla de Cassandra es análoga a una tabla en el mundo relacional.
Ahora no necesitamos almacenar un valor para cada columna cada vez que almacenamos una nueva entidad. Quizás no sepamos los valores de cada columna para una entidad dada. Por ejemplo, algunas personas tienen un segundo número de teléfono y otras no, y en lugar de almacenar el valor nulo para aquellos valores que no conocemos, lo que desperdiciaría espacio, simplemente no almacenaremos esa columna para esa fila. Así que ahora tenemos una estructura de matriz multidimensional dispersa que se parece a la siñguiente figura :

Al diseñar una tabla en una base de datos relacional tradicional, normalmente se trata de "entidades" o del conjunto de atributos que describen un nombre particular (hotel, usuario, producto, etc.). No se piensa mucho en el tamaño de las filas en sí, porque el tamaño de la fila no es negociable una vez que haya decidido qué sustantivo representa su tabla. Sin embargo, cuando trabajas con Cassandra, realmente tienes que tomar una decisión sobre el tamaño de tus filas: pueden ser anchas o delgadas, dependiendo del número de columnas que contenga la fila.
Una fila ancha significa una fila que tiene muchos y muchos (quizás decenas de miles o incluso millones) de columnas. Normalmente, hay un número menor de filas que van junto con tantas columnas. A la inversa, podría tener algo más cercano a un modelo relacional, donde define un número menor de columnas y usa muchas filas diferentes, es decir, el modelo delgado.
En Cassandra, tenemos estas estructuras de datos básicas :
- La columna, que es un par de nombre / valor
- La fila, que es un contenedor para columnas referenciadas por una clave primaria
- La tabla, que es un contenedor para filas.
- El keyspace, que es un contenedor para tablas.
- El clúster, que es un contenedor para espacios de claves que abarca uno o más nodos
jueves, 30 de mayo de 2019
Libros de Java Geeks
Download IT Guides!
|
|


|
|


domingo, 26 de mayo de 2019
Que son los System Keyspaces en Cassandra?

Si vamos a cqlsh y echamos un vistazo rápido a las tablas System Keyspaces en Cassandra, si hacemos :
cqlsh> DESCRIBE TABLES;
Al observar estas tablas, vemos que muchas de ellas están relacionadas con los conceptos que se analizado en post anteriores :
- La información sobre la estructura del clúster comunicada a través de gossip se almacena en system.local y system.peers. Estas tablas contienen información sobre el nodo local y otros nodos en el clúster, incluidas direcciones IP, ubicaciones por centro de datos y rack, CQL y versiones de protocolo.
- system.range_xfers y system.available_ranges rastrean los rangos de token administrados por cada nodo y cualquier rango que necesite asignación.
- Los system_schema.keyspaces, system_schema.tables y system_schema.columns almacenan las definiciones de los espacios de claves, tablas e índices definidos para el clúster.
- La construcción de vistas materializadas se rastrea en las tablas system.materialized_views_builds_in_progress y system.built_materialized_views, lo que da como resultado las vistas disponibles en system_schema.materialized_views.
- Extensiones proporcionadas por el usuario, como system_schema.types para tipos definidos por el usuario, system_schema.triggers para activadores configurados por tabla, system_schema. funciones para funciones definidas por el usuario, y system_schema.aggregates para agregados definidos por el usuario.
- La tabla system.paxos almacena el estado de las transacciones en curso, mientras que la tabla system.batchlog almacena el estado de los lotes atómicos.
Volvamos a cqlsh para echar un vistazo rápido a los atributos System Keyspaces de Cassandra:
cqlsh> USE system;
cqlsh:system> DESCRIBE KEYSPACE;
CREATE KEYSPACE system WITH replication = {'class': 'LocalStrategy'} AND durable_writes = true;
...
Al observar la primera declaración en la salida, vemos que el espacio System Keyspaces está usando la estrategia de replicación LocalStrategy, lo que significa que esta información está destinada para uso interno y no se replica en otros nodos.
Clases que componen Apache Cassandra Parte 2

Y llego la continuación del post "Clases que componen Apache Cassandra"
El Protocolo nativo CQL es el protocolo binario utilizado por los clientes para comunicarse con Cassandra. El paquete org.apache.cassandra.transport contiene las clases que implementan este protocolo, incluido el Servidor. Este servidor de transporte nativo administra las conexiones de clientes y enruta las solicitudes entrantes, delegando el trabajo de realizar consultas al StorageProxy.
Hay varias otras clases que manejan las características clave de Cassandra. Aquí hay algunos para investigar si estás interesado:

Clases que componen Apache Cassandra

Hay un conjunto de clases que forman los mecanismos básicos de control interno de Cassandra. Ya nos hemos encontrado con algunos de ellos en post anteriores, incluidos Hinted HandOffManager, CompactionManager y StageManager. Aquí presentamos una breve descripción de algunas otras clases para que pueda familiarizarse con algunas de las más importantes. Muchos de ellos exponen los MBeans a través de Java Management Extension (JMX) para informar el estado y las métricas y, en algunos casos, permitir la configuración y el control de sus actividades.
La interfaz org.apache.cassandra.service.CassandraDaemon representa el ciclo de vida del servicio Cassandra ejecutándose en un solo nodo. Incluye las operaciones típicas de ciclo de vida que se podrían esperar: iniciar, detener, activar, desactivar y destruir.
También puede crear una instancia de Cassandra en memoria mediante programación utilizando la clase org.apache.cassandra.service.EmbeddedCassandraService. Crear una instancia embebida puede ser útil para los programas de prueba unitaria que usan Cassandra.
La funcionalidad de almacenamiento de datos principal de Cassandra se conoce comúnmente como el motor de almacenamiento, que consiste principalmente en clases en el paquete org.apache.cassandra.db. El punto de entrada principal es la clase ColumnFamilyStore, que administra todos los aspectos del almacenamiento de tablas, incluidos los registros de confirmación, memtables, SSTables e índices.
Cassandra encasula el motor de almacenamiento en servicio representado por la
clase org.apache.cassandra.service.StorageService. El servicio de almacenamiento contiene el token del nodo, que es un marcador que indica el rango de datos de los que es responsable el nodo.
El servidor se inicia con una llamada al método initServer de esta clase, en el que el servidor registra los controladores SEDA, realiza algunas determinaciones sobre su estado (por ejemplo, si fue un programa de arranque o no, y cuál es su particionador), y registra un MBean con el servidor JMX.
El propósito de org.apache.cassandra.net.MessagingService es crear listeners de socket para el intercambio de mensajes; los mensajes entrantes y salientes de este nodo llegan a través de este servicio. El método MessagingService.listen crea un hilo. Cada conexión entrante luego se sumerge en el grupo de subprocesos ExecutorService usando org.apache.cassandra.net.IncomingTcpConnection (una clase que extiende Thread) para deserializar el mensaje. El mensaje se valida y luego se enruta al controlador apropiado.
Debido a que MessagingService también hace un uso intensivo de las etapas y el grupo que mantiene está envuelto con un MBean, puede descubrir mucho sobre cómo está funcionando este servicio (si las lecturas se están respaldando y demás) a través de JMX.
La transmisión por secuencias es la forma optimizada de Cassandra de enviar secciones de archivos SSTable de un nodo a otro a través de una conexión TCP persistente; todas las demás comunicaciones entre nodos se producen a través de mensajes serializados. org.apache.cassandra.streaming.StreamManager maneja estos mensajes de transmisión, incluida la administración de la conexión, la compresión de mensajes, el seguimiento de progreso y las estadísticas.
Nos quedan unas cuantas clases que seguiremos viendo en una parte 2.
Suscribirse a:
Entradas (Atom)
