
// Primero leo el archivo
csvPath <- "/home/spark/filmsCount.csv/part.csv"
df <- read.df(csvPath, "csv", header = "false", inferSchema = "true")
//Luego imprimo sus valores para saber que están bien.
head(df)
showDF(df)
//Ahora transformo el dataframe de spark a un dataframe plano de R
dfR <- collect(df) //Es importante pasar de dataframe de spark a dataframe de R
//Importo la librería de plot de R
library('txtplot')
//Gráfico la densidad a los 20 primeros valores.
txtdensity( dfR[1:20,2] )
//Gráfico la densidad a todos los valores.
txtdensity( dfR[,2] )
//Gráfico la densidad a todos los valores con un barchart
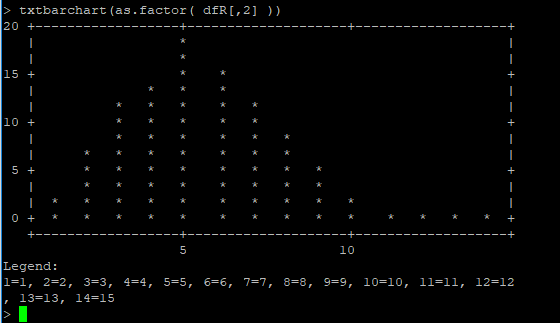
txtbarchart(as.factor( dfR[,2] ))
Y listo!!
Y te queda así :



No hay comentarios.:
Publicar un comentario