Download IT Guides!
|
miércoles, 14 de agosto de 2019
Libros gratis de Java Code Geeks




lunes, 12 de agosto de 2019
Haciendo aplicaciones políglotas con GraalVM

GraalVM permite compartir el mismo runtime, eliminando la aislamiento y permitiendo la interoperabilidad entre programas que estén escritos en diferente lenguajes. Puede correr como “standalone” o por medio de la Open-Jdk o Node.js o por la base de datos oracle.
GraalVM permite escribir poliglotas programas con cero overhead y con alta interoperabilidad. De esta manera que se pueden escribir diferentes partes del código en diferentes lenguajes.
const express = require('express');
const app = express();
app.listen(3000);
app.get('/', function(req, res) {
var text = 'Hello World!';
const BigInteger = Java.type(
'java.math.BigInteger');
text += BigInteger.valueOf(2)
.pow(100).toString(16);
text += Polyglot.eval(
'R', 'runif(100)')[0];
res.send(text);
})
También podemos crear imágenes de nuestras aplicaciones Java, lo que permite que corran mucho más rápido, en una plataforma determinada.
$ javac HelloWorld.java
$ time java HelloWorld
user 0.070s
$ native-image HelloWorld
$ time ./helloworld
user 0.005s
GraalVm puede ser embebido en aplicaciones Java que utilicen el openjdk o node.js o base de datos oracle. De esta manera podemos ejecutar código de otro lenguaje :
import org.graalvm.polyglot.*;
public class HelloPolyglot {
public static void main(String[] args) {
System.out.println("Hello Java!");
Context context = Context.create();
context.eval("js",
"print('Hello JavaScript!');");
}
}
Es muy bueno, dejo el link:
https://www.graalvm.org/
sábado, 10 de agosto de 2019
Unificando el modelo de programación de motores mapreduce con Apache Beam

Ahora bien en un momento nos enteramos que nuestra aplicación funcionaria mejor con Apache Flink o por un tema comercial queremos migrar a Cloud Dataflow de google, no sé la realidad cambia y nosotro no vamos a poder cambiar tan fácil de tecnología, porque estamos atrapados en nuestros RDDs y en el contexto de Spark.
Por esta razón se invento Apache Beam, la idea es unificar el modelo de programación de frameworks map-reduce, streams o big data en general para poder migrar fácilmente de framework a framework.
Apache Beam es un modelo unificado de código abierto para definir tuberías de procesamiento paralelo de datos por lotes y de transmisión. Usando el SDK de Beam, creamos un programa que define tuberías que es ejecutada por uno de los back-end de procesamiento distribuido compatibles con Apache Apex, Apache Flink, Apache Spark y Google Cloud Dataflow. Además Apache Beam SDK es de código abierto.
Beam es particularmente útil para tareas paralelas de procesamiento de datos, en las que el problema se puede descomponer en muchos paquetes más pequeños de datos que se pueden procesar de forma independiente y en paralelo. También puede usar Beam para tareas de Extracción, Transformación y Carga (ETL) e integración de datos puros. Estas tareas son útiles para mover datos entre diferentes medios de almacenamiento y fuentes de datos, transformar datos en un formato más deseable o cargar datos de un sistema.
Los SDK de Beam proporcionan un modelo de programación unificado que puede representar y transformar conjuntos de datos de cualquier tamaño, ya sea que la entrada sea un conjunto de datos finito de una fuente de datos por lotes o un conjunto de datos infinito de una fuente de datos de transmisión (streams). Los SDK de Beam utilizan las mismas clases para representar datos acotados y no acotados, y las mismas transformaciones funcionan para esos datos.
Beam actualmente admite los siguientes lenguajes:
- Java Java logo
- Python Python logo
- Go
- Scala por medio de la librería Scio.
Algo importante es que tenemos un sdk por lenguaje, y es medio obvio dado que esto no corre solo sobre la jdk. Esto me suena tramposo porque no es que para todos los lenguajes tenes todos los frameworks. Sino que para algunos lenguajes tenes algunos frameworks de esa tecnología.

Los Beam Pipeline Runners traducen la tubería de procesamiento de datos al framework back-end que deseemos. Cuando ejecute su programa Beam, deberá especificar un corredor apropiado para el back-end.
Beam actualmente admite Runners que funcionan con los siguientes back-end de procesamiento distribuido:
- Apache Apex
- Apache Flink
- Apache Gearpump (incubating)
- Apache Samza
- Apache Spark
- Google Cloud Dataflow
- Hazelcast Jet
Dejo link: https://beam.apache.org/
jueves, 8 de agosto de 2019
Se encuentran abiertas las inscripciones para los cursos Gugler!!!
| Me llego este mail de los amigos de Gugler : | |||||
| PRENSA GUGLER LAB 20192019 | |||||
Estimado Goette Emanuel : Las clases estarían iniciándose el martes 3, miércoles 4, jueves 5, viernes 6 o sábado 7 de Septiembre, según el curso y modalidad que elegiste. Inscribirte: clic aquí Cursos, Horarios y comisiones: clic aquí. | Dictamos nuestros cursos en la Facultad de Ciencia y Tecnología, perteneciente a la Universidad Autónoma de Entre Ríos. En nuestro portafolio de capacitación encontrarás: MODALIDAD PRESENCIAL
| ||||
| Si deseas comunicarte con nosotros, te recordamos que podes hacerlo a través de los siguientes portales, en los cuales encontrarás información sobre Gugler. TEL: (0343) - 4975066 Interno 119 Sitio Oficial: www.gugler.com.ar Campus: campusvirtual.gugler.com.ar Sistema de Gestión Cursos: sgc.gugler.com.ar Sistema de Gestión Cursos Móvil: Aquí Sistema de Documentación: sgd.gugler.com.ar Sistema de Validación: giua.gugler.com.ar |
| ||||
| GUGLER PRESS | |||||

sábado, 3 de agosto de 2019
Componiendo funciones con Factor

La composición de funciones es un concepto muy importante permite dividir las funciones en funciones más pequeñas y comenzar con la entrada, pásela a través de una serie de funciones y obtener una salida de esta manera la salida de una función es la entrada a la siguiente función y así sustantivamente hasta obtener la salida. Por lo tanto cada función es pequeña y enfocada. Se resuelve problemas creando y conectando bloques de código.
Veamos un ejemplo pero primero JavaScript :
ar x = f(42);
var y = g(x);
return h(y);
o más resumido:
return h(g(f(42)));
En factor sería :
42 f g h
Sin nombres de variables y sin paréntesis, puntos o cualquier otro signo de puntuación para indicar la composición de la función. Se da a entender que el resultado de llamar a una función (llamada word o "palabra" en Factor) . Factor maneja esto automáticamente utilizando una pila, que es simplemente un contenedor que contiene valores. Una palabra toman su entrada de la pila y empujan su resultado a la pila, que luego es operada por la siguiente palabra.
Observe también que las palabras f g h se llaman en el mismo orden en que las leemos, de izquierda a derecha.
Esta llamada se puede ver como el pipe operator de Elixir :
other_function(2) |> new_function() |> baz() |> bar() |> foo()
o el pipe operator de linux donde la salida de una operación es la entrada para otra, podemos hacer :
$ history | grep "apt"
En la versión de JavaScript, f es una función, y los paréntesis en f (42) indican que se aplica f al valor 42. Esto hace que JavaScript sea un lenguaje aplicativo. La mayoría de los otros lenguajes, como Java, Ruby, Python, Clojure, Scala, Haskell y Erlang, son aplicativos.
Factor es un lenguaje concatenante porque en lugar de aplicar funciones (o palabras), las concatena, simplemente escribiéndolas una tras otra.
La composición de funciones es la forma predeterminada de tratar una expresión como f g h. Otros lenguajes concatenativos incluyen Forth, Joy, PostScript, Cat, Om, Retro y Kitten. Si está familiarizado con Forth o Joy, notará algunas similitudes en Factor.
En lugar de escribir :
wrapWordsAsList (capitalize (strip (text)))
puedes escribir :
text strip capitalize wrapWordsAsList
Es una hermosa expresión!!!
Dejo link: https://factorcode.org/
jueves, 1 de agosto de 2019
Ploteando un dataframe con R en Spark.

// Primero leo el archivo
csvPath <- "/home/spark/filmsCount.csv/part.csv"
df <- read.df(csvPath, "csv", header = "false", inferSchema = "true")
//Luego imprimo sus valores para saber que están bien.
head(df)
showDF(df)
//Ahora transformo el dataframe de spark a un dataframe plano de R
dfR <- collect(df) //Es importante pasar de dataframe de spark a dataframe de R
//Importo la librería de plot de R
library('txtplot')
//Gráfico la densidad a los 20 primeros valores.
txtdensity( dfR[1:20,2] )
//Gráfico la densidad a todos los valores.
txtdensity( dfR[,2] )
//Gráfico la densidad a todos los valores con un barchart
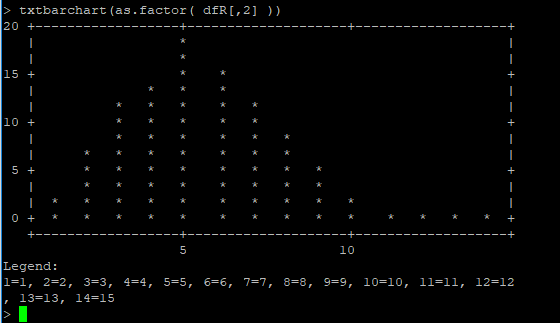
txtbarchart(as.factor( dfR[,2] ))
Y listo!!
Y te queda así :


Primeros pasos con Flutter parte 3, más Flutter que nunca!

Veamos el directorio de un proyecto en Flutter.
Directorio lib, donde va a estar toda la acción de desarrollo, y el archivo main.dart el cual es el punto de entrada de ejecución de la aplicación.
También podemos ver:
Directorios Android / IOS: contienen proyectos generados, 100% nativos, que pueden abrirse en las IDE correspondientes a cada plataforma.
Assets: Directorio para incluir imágenes/fuentes. Todos los archivos en esta carpeta se incluirán de manera automática en el bundle final. También podemos agregar directorios y archivos.
Test: Directorio para clases y archivos de unit testing.
 El archivo main es el punto de entrada de una aplicación. El runtime buscara el método “main” dentro de este archivo y debe invocar el método runApp con un widget.
El archivo main es el punto de entrada de una aplicación. El runtime buscara el método “main” dentro de este archivo y debe invocar el método runApp con un widget.En flutter, todo es un widget. Un icono, una imagen, un botón y hasta los elementos de layout, como un contenedor, una Column, Row o un Stack todos son widgets; y tanto cada pantalla como nuestra app final, será simplemente, una composición de dichos widgets.
Un widget es representado por una clase, que debe heredar de la clase del framework StatelessWidget o StatefulWidget (dependiendo de si nuestro widget tiene información estado o no), y debe además sobrescribir el método build. Dicho método debe estar en todo widget, y debe retornar un Widget.
Cada widget puede contener un hijo, que se especifica en su propiedad child. En el caso de algunos widgets de layout como “Row” o “Column”, se pueden especificar varios widgets hijos, en la propiedad children. Flutter construye los widgets a modo de árbol, invocando el método build de cada widget.
El manejo de estado más básico de un widget en Flutter, se hace mediante llamados al método setState. SetState notifica al framework del cambio de estado, y redibuja los widgets que sean necesarios.
El manejo de estado mediante el método setState puede funcionar para aplicaciones muy pequeñas, o para manejo de estado relacionado al widget en sí, Flutter ofrece mejores maneras para manejo de estado más complejo.
 Una pregunta muy común que surge a la hora de ver setState como método de manejo de estado es, ¿“Que pasa si quiero compartir información entre pantallas y widgets?” Si bien siempre podemos pasar la información mediante parámetros en los constructores, es una solución poco práctica y engorrosa. Para eso, Flutter ofrece Inherited Widget
Una pregunta muy común que surge a la hora de ver setState como método de manejo de estado es, ¿“Que pasa si quiero compartir información entre pantallas y widgets?” Si bien siempre podemos pasar la información mediante parámetros en los constructores, es una solución poco práctica y engorrosa. Para eso, Flutter ofrece Inherited WidgetAntes hablamos como los widgets en Flutter se anidan y estructuran en un árbol. Para que un widget pueda acceder a otro que se encuentra arriba en el árbol es que tenemos Inherited Widget. A nivel de código, no es más que otro widget, simplemente debe heredar de la clase InheritedWidget e implementar el método updateShouldNotify, para definir condicionalmente cuando disparar la notificación de update.
Con este código, ya tenemos un widget que puede ser accedido por todos los widgets hijos en el árbol. El acceso al InheritedWidget se logra utilizando el método “of”. Claramente leyéndolo así suena todo muy abstracto, en un próximo post vamos con un ejemplo.
Dejo link: https://flutter.dev
SASI : Una nueva implementación del índice secundario en Cassandra

La versión Cassandra 3.4 incluía una implementación alternativa de índices secundarios conocida como SSTable Attached Secondary Index (SASI). SASI fue desarrollado por Apple y lanzado como una implementación de código abierto de la API del índice secundario de Cassandra. Como su nombre lo indica, los índices SASI se calculan y almacenan como parte de cada archivo SSTable, a diferencia de la implementación original de Cassandra, que almacena los índices en tablas separadas, "ocultas".
La implementación SASI existe junto con los índices secundarios tradicionales, y puede crear un índice SASI con el comando CQL CREATE CUSTOM INDEX:
CREATE CUSTOM INDEX user_last_name_sasi_idx ON user (last_name)
USING 'org.apache.cassandra.index.sasi.SASIIndex';
Los índices SASI ofrecen funcionalidad más allá de la implementación de índice secundario tradicional, como la capacidad de realizar búsquedas de desigualdad (mayor o menor que) en columnas indexadas. También puede utilizar la nueva palabra clave "LIKE" para realizar búsquedas de texto en columnas indexadas. Por ejemplo, podría usar la siguiente consulta para encontrar usuarios cuyo apellido comience con "N":
SELECT * FROM user WHERE last_name LIKE 'N%';
Si bien los índices SASI se desempeñan mejor que los índices tradicionales al eliminar la necesidad de leer de tablas adicionales, aún requieren lecturas de un mayor número de nodos que un diseño desnormalizado.
Libres Gratuitos!!!
|




domingo, 28 de julio de 2019
Deep Learning vs. Machine Learning: elegir el mejor enfoque

Quiero recomendar un libro/pagina gratuito sobre machine learning y deep learning, es provisto por la empresa MathWorks que es la responsable de Mathlab.
Si van a la pagina van a poder leer:
" Tiene datos, hardware y un objetivo: todo lo que necesita para implementar los algoritmos de Machine Learning y de Deep Learning. ¿Pero cuál debería usar?
Este ebook interactivo tiene un enfoque centrado en el usuario para guiarlo hacia los algoritmos que debe considerar desde el principio.
Aprenda qué algoritmos están asociados con seis tareas comunes, que incluyen:
- Predicción de una salida basada en datos históricos
- Identificación de objetos en imagen, video y datos de señal
- Moverse físicamente o en una simulación "
Como dice en la descripción es un libro interactivo por lo que no tenemos un formato "pdf" sino que es una pagina, con videos, links y ejemplos interactivos.
Muy recomendable.
Dejo link:
https://la.mathworks.com/campaigns/offers/deep-learning-vs-machine-learning-algorithm.html
jueves, 25 de julio de 2019
Mezclando datos de diferentes almacenes de datos con Apache Spark SQL

Vamos a hacer un ejemplo con Apache Spark SQL. Algo simple, vamos a tomar algunas tablas de una base de datos relacional y vamos hacer unas consultas y luego vamos a importar datos de un csv para tambien hacer consultas:
//Primero importamos la clase de SQLContext y creamos el contexto.
import org.apache.spark.sql.SQLContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
//Vamos a importar los datos de la base de datos, en este caso la tabla "actor"
val url = "jdbc:mysql://0.0.0.0:3306/sakila"
val dfActor = spark.read.format("jdbc").option("url", url)
.option("dbtable", "actor")
.option("user", "sparkDb")
.option("password","sparkDb").load()
//Ya tenemos la tabla en el dataframe ahora vamos a imprimir el esquema y ver los datos.
dfActor.printSchema()
dfActor.show()
dfActor.count()
//Consultamos el campo nombre
dfActor.select("first_name").show()
//Registramos la tabla para poder consultarla con SQL
dfActor.registerTempTable("actors")
// Y consultamos
spark.sql("select first_name, last_name from actors").show
//Vamos a traernos una tabla relación entre el actor y el film
val dfActorFilms = spark.read.format("jdbc").option("url", url).option("dbtable", "film_actor").option("user", "sparkDb").option("password","sparkDb").load()
//Registro la tabla temporal
dfActorFilms.registerTempTable("actors_films")
//Selecciono los datos del actor y en cuantas peliculas actuo
spark.sql("select a.first_name, a.last_name, count(af.film_id) from actors a join actors_films af on (a.actor_id=af.actor_id) group by a.first_name, a.last_name").show
// Ahora vamos a traernos los datos del film pero desde un archivo csv
// Creamos una clase que me va hacer util leer los datos de forma estructurada.
case class Film(film_id: Int, title: String, description: String, release_year: Int)
// Leemos el archivo CSV :
val dfFilms = sc.textFile("/home/spark/films.csv").map(_.split(",")).map(p => Film(p(0).trim.toInt, p(1), p(2), p(3).trim.toInt)).toDF()
// Vemos que tiene el archivo
dfFilms.show
//Registramos el dataframe para poder hacer consultas sobre él
dfFilms.registerTempTable("films")
//Realizamos una consulta con joins al datafame actos_films para saber cuantos actores trabajaron en los films.
val dfFilmsCountActors = spark.sql("select f.title, count(af.film_id) from films f join actors_films af on (f.film_id=af.film_id) group by f.title")
//Registramos el dataframe como una tabla temporal
dfFilmsCountActors.registerTempTable("films_Count_Actors")
//Hacemos una consulta sobre esa tabla con filtro.
spark.sql("select * from films_Count_Actors fca where fca.title like '%SANTA%' ").show
//Por ultimo exportamos este resultado.
dfFilmsCountActors.coalesce(1).write.csv("/home/spark/filmsCount.csv")
Fin!
La idea era poder hacer un conjunto de acciones que nos sirvan como ejemplo de las cosas que se pueden hacer con Spark SQL. Espero que les sirva!!
martes, 23 de julio de 2019
VoltDb regala un libro
La gente de VoltDb una base NewSQL me regala un libro y quiero compartir con ustedes. Me llego el siguiente mail :
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


Como puedo exportar un dataframe a un archivo en Apache Spark??

Tuve que exportar un dataframe a un archivo csv es spark y con scala, como no sabia lo tuve que buscar y ahora te lo comparto. En Spark 2 simplemente podemos hacer lo siguiente:
df.write.csv ("/la/carpeta/donde/queremos/que/este/el/archivo")
Si deseamos asegurarnos que el archivo sea uno, es decir que ya no estén particionados, agregue un .coalesce (1) de la siguiente manera;
df.coalesce (1) .write.csv ("/la/carpeta/donde/queremos/que/este/el/archivo")
Espero que les sea de ayuda!!
Apache NetBeans 11.1 fue liberado

La nueva versión cuenta con soporte para la sintaxis Java 11 y 12, así como una estrecha integración con los proyectos Jakarte EE / Java EE 8 a través de los servidores de aplicaciones Payara y Glassfish. Los proyectos se pueden crear directamente a través de Maven y Gradle, utilizando el nuevo arquetipo webapp-javaee8. Esto permite a los desarrolladores trabajar y depurar aplicaciones completamente a través de los sistemas de compilación nativos, en lugar de un archivo de proyecto separado que emula al sistema de compilación.
Los desarrolladores de aplicaciones móviles o de escritorio pueden aprovechar la contribución de Gluon de las muestras de OpenJFX en NetBeans. Combinado con la comunidad GraalVM, OpenJFX permite a los desarrolladores codificar en Java y crear ejecutables nativos que se ejecutan directamente en dispositivos móviles. Usando NetBeans, los desarrolladores pueden crear y depurar estas aplicaciones antes de la implementación dentro de las tiendas de aplicaciones móviles. NetBeans también contribuyó a la creación de GraalVM este permite la visualización de gráficos de dependencia de programas, basados en la plataforma NetBeans.
NetBeans tambien ofrece soporte para el desarrollo JavaScript en el lado del cliente o servidor, así como soporte nativo para aplicaciones PHP 7.4.
Y ya podemos bajarlo dejo link :
https://netbeans.apache.org/
http://netbeans.apache.org/download/nb111/index.html
domingo, 21 de julio de 2019
Primeros pasos con Flutter parte 2, la venganza de Flutter
Ahora voy a utilizar Android studio. Ya aprendi la lección lo mejor es utilizar Android Studio si queremos renegar menos. Antes que nada debemos instalar el sdk, como lo instalamos en el post anterior.
Primero instalar android studio, se puede bajar de aquí o yo en mi caso lo instale del market de linux:
Al iniciar android studio vamos a intalar el plugin de flutter :

Ahi elegimos el plugin de flutter :

Y nos va a pedir instalar el plugin de Dart y le decimos que si.
Y luego reniciamos la IDE.
Ahora ponemos new Flutter Project. Y le metemos...



Como se puede ver en las imagenes es un wizard muy simple. Lo único para destacar es que tenemos que indicar donde se instalo la sdk de fluter.
Con este proyecto, el wizard crea un proyecto de ejemplo. Así que ya tenemos nuestro ejemplo ahora prodremos probarlo, peeeeeero antes debemos crear un dispocitivo a donde probarlo. Ahora tenemos que ir a AVD manager y crear el device. El wizard es simple tambien, tenemos que elegir el tipo de dispositivo, luego el sistema operativo, si no tenemos instalado ninguno te permite bajar alguno,



Y con el dispositivo, ahora si podremos probar nuestra aplicación. Listo, para cerrar el post vamos a ejecutar la aplicación y ver como funciona. Y funciona!!!

Primero instalar android studio, se puede bajar de aquí o yo en mi caso lo instale del market de linux:

Al iniciar android studio vamos a intalar el plugin de flutter :

Ahi elegimos el plugin de flutter :
Y nos va a pedir instalar el plugin de Dart y le decimos que si.
Y luego reniciamos la IDE.
Ahora ponemos new Flutter Project. Y le metemos...



Como se puede ver en las imagenes es un wizard muy simple. Lo único para destacar es que tenemos que indicar donde se instalo la sdk de fluter.
Con este proyecto, el wizard crea un proyecto de ejemplo. Así que ya tenemos nuestro ejemplo ahora prodremos probarlo, peeeeeero antes debemos crear un dispocitivo a donde probarlo. Ahora tenemos que ir a AVD manager y crear el device. El wizard es simple tambien, tenemos que elegir el tipo de dispositivo, luego el sistema operativo, si no tenemos instalado ninguno te permite bajar alguno,



Y con el dispositivo, ahora si podremos probar nuestra aplicación. Listo, para cerrar el post vamos a ejecutar la aplicación y ver como funciona. Y funciona!!!

Suscribirse a:
Entradas (Atom)
